- Stop lowercasing the field when looking in the field id map
- When a field id does not exist it means there is currently zero
documents containing this field thus we returns an empty RoaringBitmap
instead of throwing an internal error
424: Store the geopoint in three dimensions r=Kerollmops a=irevoire
Related to this issue: https://github.com/meilisearch/MeiliSearch/issues/1872
Fix the whole computation of distance for any “geo” operations (sort or filter). Now when you sort points they are returned to you in the right order.
And when you filter on a specific radius you only get points included in the radius.
This PR changes the way we store the geo points in the RTree.
Instead of considering the latitude and longitude as orthogonal coordinates, we convert them to real orthogonal coordinates projected on a sphere with a radius of 1.
This is the conversion formulae.
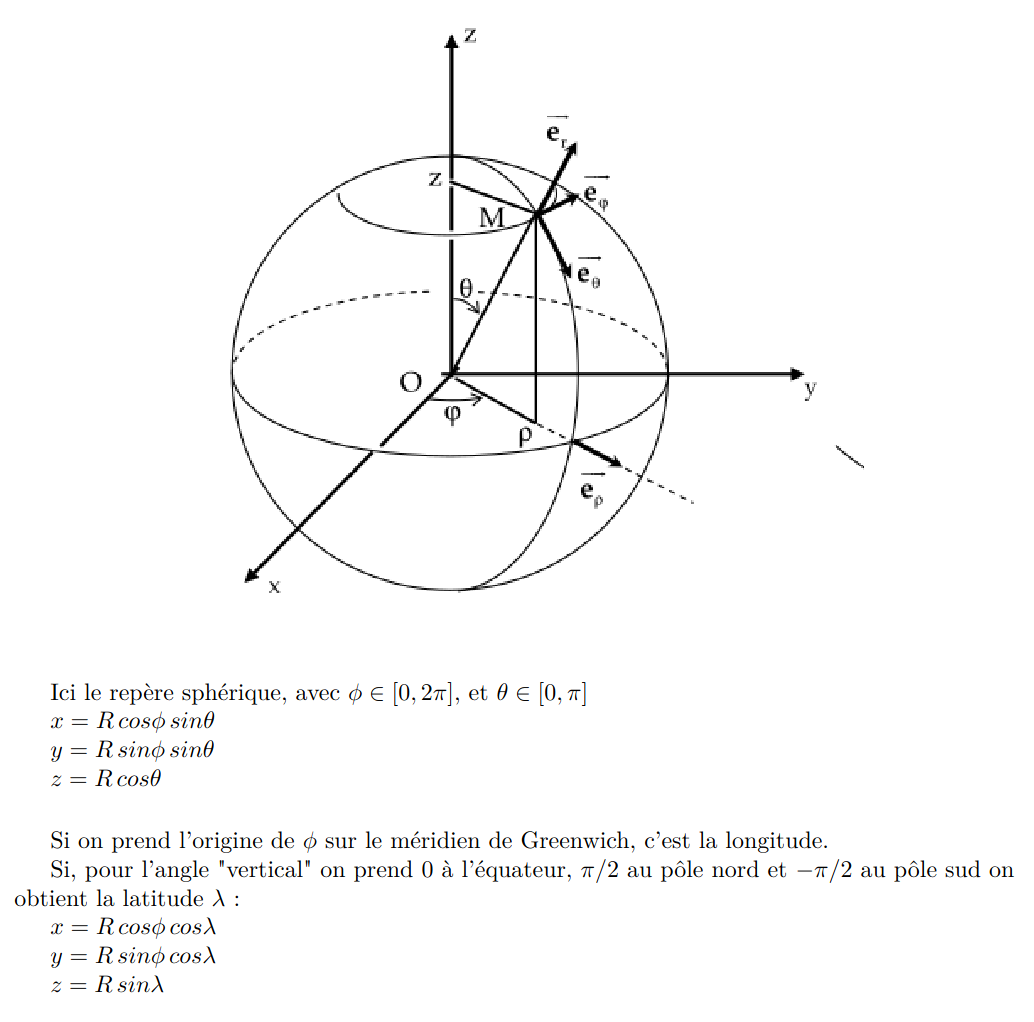
Which, in rust, translate to this function:
```rust
pub fn lat_lng_to_xyz(coord: &[f64; 2]) -> [f64; 3] {
let [lat, lng] = coord.map(|f| f.to_radians());
let x = lat.cos() * lng.cos();
let y = lat.cos() * lng.sin();
let z = lat.sin();
[x, y, z]
}
```
Storing the points on a sphere is easier / faster to compute than storing the point on an approximation of the real earth shape.
But when we need to compute the distance between two points we still need to use the haversine distance which works with latitude and longitude.
So, to do the fewest search-time computation possible I'm now associating every point with its `DocId` and its lat/lng.
Co-authored-by: Tamo <tamo@meilisearch.com>
429: Benchmark CIs: not use a default label to call the GH runner r=irevoire a=curquiza
Since we now have multiple self-hosted github runners, we need to differentiate them calling them in the CI. The `self-hosted` label is the default one, so we need to use the unique and appropriate one for the benchmark machine
<img width="925" alt="Capture d’écran 2022-01-04 à 15 42 18" src="https://user-images.githubusercontent.com/20380692/148079840-49cd7878-5912-46ff-8ab8-bf646777f782.png">
Co-authored-by: Clémentine Urquizar <clementine@meilisearch.com>
428: Reintroduce the gitignore for the fuzzer r=Kerollmops a=irevoire
Reintroduce the gitignore in the fuzz directory
Co-authored-by: Tamo <tamo@meilisearch.com>
425: Push the result of the benchmarks to influxdb r=irevoire a=irevoire
Now execute a benchmark for every PR merged into main and then upload the results to influxdb.
Co-authored-by: Tamo <tamo@meilisearch.com>
422: Prefer returning `None` instead of using an `FilterCondition::Empty` state r=Kerollmops a=Kerollmops
This PR is related to the issue comment https://github.com/meilisearch/MeiliSearch/issues/1338#issuecomment-989322889 which exhibits the fact that when a filter is known to be empty no results are returned which is wrong, the filter should not apply as no restriction is done on the documents set.
The filter system on the milli side has introduced an Empty state which was used in this kind of situation but I found out that it is not needed and that when we parse a filter and that it is empty we can simply return `None` as the `Filter::from_array` constructor does. So I removed it and added tests!
On the MeiliSearch side, we just need to match on a `None` and completely ignore the filter in such a case.
Co-authored-by: Clément Renault <clement@meilisearch.com>
421: Introduce the depth method on FilterCondition r=Kerollmops a=Kerollmops
This PR introduces the depth method on the FilterCondition type to be able to react to it. It is meant to be used to reject filters that go too deep and can make the engine stack overflow.
Co-authored-by: Clément Renault <clement@meilisearch.com>
419: fix word pair proximity indexing r=ManyTheFish a=ManyTheFish
# Pull Request
Sort positions before iterating over them during word pair proximity extraction.
fixes [Meilisearch#1913](https://github.com/meilisearch/MeiliSearch/issues/1913)
Co-authored-by: many <maxime@meilisearch.com>
418: change visibility of DocumentDeletionResult r=Kerollmops a=MarinPostma
Change the visibility of `DocumentDeletionResult`, so its fields can be accesses from outside milli.
Co-authored-by: Marin Postma <postma.marin@protonmail.com>
409: remove update_id in UpdateBuilder r=ManyTheFish a=MarinPostma
Removing the `update_id` from `UpdateBuidler`, since it serves no purpose. I had introduced it when working in HA some time ago, but I think there are better ways to do it now, so it can be removed an stop being in our way.
Co-authored-by: Marin Postma <postma.marin@protonmail.com>
414: improve update result types r=ManyTheFish a=MarinPostma
Inprove the returned meta when performing document additions and deletions:
- On document addition return the number of indexed documents and the total number of documents in the index after the indexion
- On document deletion return the number of deleted documents, and the remaining number of documents in the index after the deletion is performed
I also fixed a potential bug when performing a document deletion and the primary key couldn't be found: before we assumed that the db was empty and returned that no documents were deleted, but since we checked before that the db wasn't empty, entering this branch is actually a bug, and now returns a 'MissingPrimaryKey' error.
Co-authored-by: Marin Postma <postma.marin@protonmail.com>
returned metaimprove document addition returned metaimprove document
addition returned metaimprove document addition returned metaimprove
document addition returned metaimprove document addition returned
metaimprove document addition returned meta
400: Rewrite the filter parser and add a lot of tests r=irevoire a=irevoire
This PR is a complete rewrite of #358, which was reverted in #403.
You can already try this PR in Meilisearch here https://github.com/meilisearch/MeiliSearch/pull/1880.
Since writing a parser is quite complicated, I moved all the logic to another workspace called `filter_parser`.
In this workspace, we don't know anything about milli, the filterable fields / field ID or anything.
As you can see in its `cargo.toml`, it has only three dependencies entirely focused on the parsing part:
```
nom = "7.0.0"
nom_locate = "4.0.0"
```
But introducing this new workspace made some changes necessary on the “AST”. Now the parser only returns `Tokens` (a simple `&str` with a bit of context). Everything is interpreted when we execute the filter later in milli.
This crate provides a new error type for all filter related errors.
---------
## Errors
Currently, we have multiple kinds of errors. Sometimes we are generating errors looking like that: (for `name = truc`)
```
Attribute `name` is not filterable. Available filterable attributes are: ``.
```
While sometimes pest was generating errors looking like that:
```
Invalid syntax for the filter parameter: ` --> 1:7
|
1 | name =
| ^---
|
= expected word`.
```
Which most people were seeing like that: (for `name =`)
```
Invalid syntax for the filter parameter: ` --> 1:7\n |\n1 | name =\n | ^---\n |\n = expected word`.
```
-----------
With this PR, the error format is unified between all errors.
All errors follow this more straightforward format:
```
The error message.
[from char]:[to char] filter
```
This should be way easier to read when embedded in the JSON for a human. And it should also allow us to parse the errors easily and provide highlighting or something with a frontend playground.
Here is an example of the two previous errors with the new format:
For `name = truc`:
```
Attribute `name` is not filterable. Available filterable attributes are: ``.
1:4 name = truc
```
Or in one line:
```
Attribute `name` is not filterable. Available filterable attributes are: ``.\n1:4 name = truc
```
And for `name =`:
```
Was expecting a value but instead got nothing.
7:7 name =
```
Or in one line:
```
Was expecting a value but instead got nothing.\n7:7 name =
```
Also, since we now have control over the parser, we can generate more explicit error messages so a lot of new errors have been created. I tried to be as helpful as possible for the user; here is a little overview of the new error message you can get when misusing a filter:
```
Expression `"truc` is missing the following closing delimiter: `"`.
8:13 name = "truc
```
The `_geoRadius` filter is an operation and can't be used as a value.
8:30 name = _geoRadius(12, 13, 14)
```
etc
## Tests
A lot of tests have been written in the `filter_parser` crate. I think there is a unit test for every part of the syntax.
But since we can never be sure we covered all the cases, I also fuzzed the new parser A LOT (for ±8 hours on 20 threads). And the code to fuzz the parser is included in the workspace, so if one day we need to change something to the syntax, we'll be able to re-use it by simply running:
```
cargo fuzz run --release parse
```
## Milli
I renamed the type and module `filter_condition.rs` / `FilterCondition` to `filter.rs` / `Filter`.
Co-authored-by: Tamo <tamo@meilisearch.com>
{kind=link}
{kind=link}