3641: Bring back changes from `release v1.1.0` into `main` after v1.1.0 release r=curquiza a=curquiza
Replace https://github.com/meilisearch/meilisearch/pull/3637 since we don't want to pull commits from `main` into `release-v1.1.0` when fixing git conflicts
Co-authored-by: ManyTheFish <many@meilisearch.com>
Co-authored-by: bors[bot] <26634292+bors[bot]@users.noreply.github.com>
Co-authored-by: Charlotte Vermandel <charlottevermandel@gmail.com>
Co-authored-by: Tamo <tamo@meilisearch.com>
Co-authored-by: Louis Dureuil <louis@meilisearch.com>
Co-authored-by: curquiza <clementine@meilisearch.com>
Co-authored-by: Clément Renault <clement@meilisearch.com>
Co-authored-by: Many the fish <many@meilisearch.com>
3638: filter errors - `geo(x,y,z)` and `geoDistance(x,y,z)` r=irevoire a=cymruu
# Pull Request
## Related issue
Fixes#3006
## What does this PR do?
- fixes the display function of `ParseError::ReservedGeo`. The previous display string was missing back ticks around available filters.
- makes the filter-parser parse `_geo(x,y,z)` and `geoDistance(x,y,z)` filters. Both parsing functions will throw an error if the filter was used.
- removes `FilterError::ReservedGeo` and `FilterError::Reserved` error variants since they are now thrown by the filter-parser.
I ran `cargo test --package milli -- --test-threads 1` and the tests passed.
## PR checklist
Please check if your PR fulfills the following requirements:
- [x] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [x] Have you read the contributing guidelines?
- [ ] Have you made sure that the title is accurate and descriptive of the changes?
Thank you so much for contributing to Meilisearch!
Co-authored-by: Filip Bachul <filipbachul@gmail.com>
Co-authored-by: filip <filipbachul@gmail.com>
3631: sort errors - `_geo(x,y)` and `_geoDistance(x,y)` return `ReservedKeyword` r=irevoire a=cymruu
# Pull Request
## Related issue
Fix part of #3006 (sort errors)
## What does this PR do?
- made meilisearch return `ReservedKeyword` when sorting by `_geo(x,y)` or `_geoDistance(x,y)`
Screenshot:
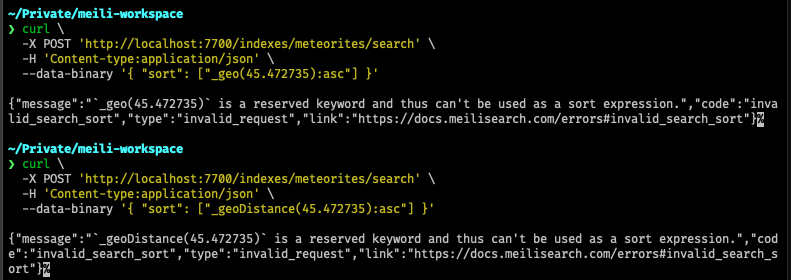
I ran `cargo test --package milli -- --test-threads 1` and the tests passed.
## PR checklist
Please check if your PR fulfills the following requirements:
- [x] Does this PR fix an existing issue, or have you listed the changes applied in the PR description (and why they are needed)?
- [x] Have you read the contributing guidelines?
- [ ] Have you made sure that the title is accurate and descriptive of the changes?
Co-authored-by: Filip Bachul <filipbachul@gmail.com>
3636: Add a newline after the meilisearch version in the issue template r=curquiza a=bidoubiwa
# Pull Request
## What does this PR do?
Just a small change that makes it easier to remove the version example and adds consistency with the other examples in its positioning.
Co-authored-by: cvermand <33010418+bidoubiwa@users.noreply.github.com>
3633: Bump Swatinem/rust-cache from 2.2.0 to 2.2.1 r=curquiza a=dependabot[bot]
Bumps [Swatinem/rust-cache](https://github.com/Swatinem/rust-cache) from 2.2.0 to 2.2.1.
<details>
<summary>Release notes</summary>
<p><em>Sourced from <a href="https://github.com/Swatinem/rust-cache/releases">Swatinem/rust-cache's releases</a>.</em></p>
<blockquote>
<h2>v2.2.1</h2>
<ul>
<li>Update <code>`@actions/cache</code>` dependency to fix usage of <code>zstd</code> compression.</li>
</ul>
</blockquote>
</details>
<details>
<summary>Changelog</summary>
<p><em>Sourced from <a href="https://github.com/Swatinem/rust-cache/blob/master/CHANGELOG.md">Swatinem/rust-cache's changelog</a>.</em></p>
<blockquote>
<h2>2.2.1</h2>
<ul>
<li>Update <code>`@actions/cache</code>` dependency to fix usage of <code>zstd</code> compression.</li>
</ul>
<h2>2.2.0</h2>
<ul>
<li>Add new <code>save-if</code> option to always restore, but only conditionally save the cache.</li>
</ul>
<h2>2.1.0</h2>
<ul>
<li>Only hash <code>Cargo.{lock,toml}</code> files in the configured workspace directories.</li>
</ul>
<h2>2.0.2</h2>
<ul>
<li>Avoid calling <code>cargo metadata</code> on pre-cleanup.</li>
<li>Added <code>prefix-key</code>, <code>cache-directories</code> and <code>cache-targets</code> options.</li>
</ul>
<h2>2.0.1</h2>
<ul>
<li>Primarily just updating dependencies to fix GitHub deprecation notices.</li>
</ul>
<h2>2.0.0</h2>
<ul>
<li>The action code was refactored to allow for caching multiple workspaces and
different <code>target</code> directory layouts.</li>
<li>The <code>working-directory</code> and <code>target-dir</code> input options were replaced by a
single <code>workspaces</code> option that has the form of <code>$workspace -> $target</code>.</li>
<li>Support for considering <code>env-vars</code> as part of the cache key.</li>
<li>The <code>sharedKey</code> input option was renamed to <code>shared-key</code> for consistency.</li>
</ul>
<h2>1.4.0</h2>
<ul>
<li>Clean both <code>debug</code> and <code>release</code> target directories.</li>
</ul>
<h2>1.3.0</h2>
<ul>
<li>Use Rust toolchain file as additional cache key.</li>
<li>Allow for a configurable target-dir.</li>
</ul>
<h2>1.2.0</h2>
<ul>
<li>Cache <code>~/.cargo/bin</code>.</li>
<li>Support for custom <code>$CARGO_HOME</code>.</li>
<li>Add a <code>cache-hit</code> output.</li>
<li>Add a new <code>sharedKey</code> option that overrides the automatic job-name based key.</li>
</ul>
<h2>1.1.0</h2>
<ul>
<li>Add a new <code>working-directory</code> input.</li>
<li>Support caching git dependencies.</li>
</ul>
<!-- raw HTML omitted -->
</blockquote>
<p>... (truncated)</p>
</details>
<details>
<summary>Commits</summary>
<ul>
<li><a href="6fd3edff69"><code>6fd3edf</code></a> 2.2.1</li>
<li><a href="a1c019f71a"><code>a1c019f</code></a> update dependencies and rebuild</li>
<li><a href="664ce0090f"><code>664ce00</code></a> chore: Create check-dist.yml (<a href="https://redirect.github.com/Swatinem/rust-cache/issues/96">#96</a>)</li>
<li>See full diff in <a href="https://github.com/Swatinem/rust-cache/compare/v2.2.0...v2.2.1">compare view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
You can trigger a rebase of this PR by commenting ``@dependabot` rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- ``@dependabot` rebase` will rebase this PR
- ``@dependabot` recreate` will recreate this PR, overwriting any edits that have been made to it
- ``@dependabot` merge` will merge this PR after your CI passes on it
- ``@dependabot` squash and merge` will squash and merge this PR after your CI passes on it
- ``@dependabot` cancel merge` will cancel a previously requested merge and block automerging
- ``@dependabot` reopen` will reopen this PR if it is closed
- ``@dependabot` close` will close this PR and stop Dependabot recreating it. You can achieve the same result by closing it manually
- ``@dependabot` ignore this major version` will close this PR and stop Dependabot creating any more for this major version (unless you reopen the PR or upgrade to it yourself)
- ``@dependabot` ignore this minor version` will close this PR and stop Dependabot creating any more for this minor version (unless you reopen the PR or upgrade to it yourself)
- ``@dependabot` ignore this dependency` will close this PR and stop Dependabot creating any more for this dependency (unless you reopen the PR or upgrade to it yourself)
</details>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
3623: Update mini-dashboard to version v0.2.7 r=curquiza a=bidoubiwa
## Changes
* Retrieve the API Key from the url parameters (#416) `@qdequele`
## 🐛 Bug Fixes
* Fix show more button not displaying all fields (#419) `@bidoubiwa`
Thanks again to `@bidoubiwa,` and `@qdequele!` 🎉
Co-authored-by: Charlotte Vermandel <charlottevermandel@gmail.com>
3624: Reduce the time to import a dump r=irevoire a=irevoire
When importing a dump, this PR does multiple things;
- Stops committing the changes between each task import
- Stop deserializing + serializing every bitmap for every task
Pros:
Importing 1M tasks in a dump went from 3m36 on my computer to 6s
Cons: We use slightly more memory, but since we’re using roaring bitmaps, that really shouldn’t be noticeable.
Fixes#3620
Co-authored-by: Tamo <tamo@meilisearch.com>
3621: Fix facet normalization r=Kerollmops a=ManyTheFish
# Pull Request
Make sure the facet normalization is the same between indexing and search.
## Related issue
Fixes#3599
Co-authored-by: ManyTheFish <many@meilisearch.com>
3608: In a settings update, check to see if the primary key actually changes before erroring out r=irevoire a=GregoryConrad
Previously, if the primary key was set and a Settings update contained a primary key, an error would be returned.
However, this error is not needed if the new PK == the current PK. This PR just checks to see if the PK actually changes before raising an error.
I came across this slight hiccup in https://github.com/GregoryConrad/mimir/issues/156#issuecomment-1484128654
Co-authored-by: Gregory Conrad <gregorysconrad@gmail.com>
Previously, if the primary key was set and a Settings update contained
a primary key, an error would be returned.
However, this error is not needed if the new PK == the current PK.
This commit just checks to see if the PK actually changes
before raising an error.
3597: ensure that the task queue is correctly imported r=irevoire a=irevoire
## Related issue
Fixes#3596
I updated all the dump's integration tests to ensure that we're effectively able to query the tasks
Co-authored-by: Tamo <tamo@meilisearch.com>
3576: Add boolean support for csv documents r=irevoire a=irevoire
Fixes https://github.com/meilisearch/meilisearch/issues/3572
## What does this PR do?
Add support for the boolean types in csv documents.
The type definition is `boolean` and the possible values are
- `true` for true
- `false` for false
- ` ` for null
Here is an example:
```csv
#id,cute:boolean
0,true
1,false
2,
```
Co-authored-by: Tamo <tamo@meilisearch.com>
3587: Enable cache again in test suite CI r=curquiza a=curquiza
Following the change in this PR introduced in v1.1: https://github.com/meilisearch/meilisearch/pull/3422
The cache was removed due to failures (lack of space). Now the binary is smaller (from 250Mb to 50Mb) we want to try to enable the cache again.
Indeed, without the cache step, the CIs are wayyyy slower (45min instead of 20-30min).
For later: Rust 1.68 introduced a new way to fetch crates. Updating the rust version might also help in the future!
Co-authored-by: curquiza <clementine@meilisearch.com>
3568: CI: Fix `publish-aarch64` job that still uses ubuntu-18.04 r=Kerollmops a=curquiza
Fixes#3563
Main change
- add the usage of the `ubuntu-18.04` container instead of the native `ubuntu-18.04` of GitHub actions: I had to install docker in the container.
Small additional changes
- remove useless `fail-fast` and unused/irrelevant matrix inputs (`build`, `linker`, `os`, `use-cross`...)
- Remove useless step in job
Proof of work with this CI triggered on this current branch: https://github.com/meilisearch/meilisearch/actions/runs/4366233882
3569: Enhance Japanese language detection r=dureuill a=ManyTheFish
# Pull Request
This PR is a prototype and can be tested by downloading [the dedicated docker image](https://hub.docker.com/layers/getmeili/meilisearch/prototype-better-language-detection-0/images/sha256-a12847de00e21a71ab797879fd09777dadcb0881f65b5f810e7d1ed434d116ef?context=explore):
```bash
$ docker pull getmeili/meilisearch:prototype-better-language-detection-0
```
## Context
Some Languages are harder to detect than others, this miss-detection leads to bad tokenization making some words or even documents completely unsearchable. Japanese is the main Language affected and can be detected as Chinese which has a completely different way of tokenization.
A [first iteration has been implemented for v1.1.0](https://github.com/meilisearch/meilisearch/pull/3347) but is an insufficient enhancement to make Japanese work. This first implementation was detecting the Language during the indexing to avoid bad detections during the search.
Unfortunately, some documents (shorter ones) can be wrongly detected as Chinese running bad tokenization for these documents and making possible the detection of Chinese during the search because it has been detected during the indexing.
For instance, a Japanese document `{"id": 1, "name": "東京スカパラダイスオーケストラ"}` is detected as Japanese during indexing, during the search the query `東京` will be detected as Japanese because only Japanese documents have been detected during indexing despite the fact that v1.0.2 would detect it as Chinese.
However if in the dataset there is at least one document containing a field with only Kanjis like:
_A document with only 1 field containing only Kanjis:_
```json
{
"id":4,
"name": "東京特許許可局"
}
```
_A document with 1 field containing only Kanjis and 1 field containing several Japanese characters:_
```json
{
"id":105,
"name": "東京特許許可局",
"desc": "日経平均株価は26日 に約8カ月ぶりに2万4000円の心理的な節目を上回った。株高を支える材料のひとつは、自民党総裁選で3選を決めた安倍晋三首相の経済政策への期待だ。恩恵が見込まれるとされる人材サービスや建設株の一角が買われている。ただ思惑が先行して資金が集まっている面 は否めない。実際に政策効果を取り込む企業はどこか、なお未知数だ。"
}
```
Then, in both cases, the field `name` will be detected as Chinese during indexing allowing the search to detect Chinese in queries. Therefore, the query `東京` will be detected as Chinese and only the two last documents will be retrieved by Meilisearch.
## Technical Approach
The current PR partially fixes these issues by:
1) Adding a check over potential miss-detections and rerunning the extraction of the document forcing the tokenization over the main Languages detected in it.
> 1) run a first extraction allowing the tokenizer to detect any Language in any Script
> 2) generate a distribution of tokens by Script and Languages (`script_language`)
> 3) if for a Script we have a token distribution of one of the Language that is under the threshold, then we rerun the extraction forbidding the tokenizer to detect the marginal Languages
> 4) the tokenizer will fall back on the other available Languages to tokenize the text. For example, if the Chinese were marginally detected compared to the Japanese on the CJ script, then the second extraction will force Japanese tokenization for CJ text in the document. however, the text on another script like Latin will not be impacted by this restriction.
2) Adding a filtering threshold during the search over Languages that have been marginally detected in documents
## Limits
This PR introduces 2 arbitrary thresholds:
1) during the indexing, a Language is considered miss-detected if the number of detected tokens of this Language is under 10% of the tokens detected in the same Script (Japanese and Chinese are 2 different Languages sharing the "same" script "CJK").
2) during the search, a Language is considered marginal if less than 5% of documents are detected as this Language.
This PR only partially fixes these issues:
- ✅ the query `東京` now find Japanese documents if less than 5% of documents are detected as Chinese.
- ✅ the document with the id `105` containing the Japanese field `desc` but the miss-detected field `name` is now completely detected and tokenized as Japanese and is found with the query `東京`.
- ❌ the document with the id `4` no longer breaks the search Language detection but continues to be detected as a Chinese document and can't be found during the search.
## Related issue
Fixes#3565
## Possible future enhancements
- Change or contribute to the Library used to detect the Language
- the related issue on Whatlang: https://github.com/greyblake/whatlang-rs/issues/122
Co-authored-by: curquiza <clementine@meilisearch.com>
Co-authored-by: ManyTheFish <many@meilisearch.com>
Co-authored-by: Many the fish <many@meilisearch.com>
3577: Avoid fetching an LMDB value with an empty string r=ManyTheFish a=Kerollmops
# Pull Request
## Related issue
Fixes#3574
## What does this PR do?
This PR fixes a bug where an empty key fetches an entry in the database. LMDB throws an error if an empty or too-long key is used to fetch an entry. This empty string seems to have been generated by the Charabia tokenizer.
Co-authored-by: Clément Renault <clement@meilisearch.com>
{kind=link}