462: cli improvements r=Kerollmops a=MarinPostma
a few improvements:
- use bufreader to load documents, so the loading of the document doesn't appear on flamegraphs
- set default db path to current directory so the `-i` flag can be omitted.
Co-authored-by: ad hoc <postma.marin@protonmail.com>
459: Update heed link in cargo toml r=Kerollmops a=curquiza
Since grenad and heed have been moved to the meilisearch orga, this PR changes the link.
This is a minor change since GitHub handles automatically the redirection. This PR is only for consisitency.
Co-authored-by: Clémentine Urquizar <clementine@meilisearch.com>
456: Remove useless grenad merging r=Kerollmops a=Kerollmops
This PR must be merged after #454.
This PR removes the part of code that was merging all of the grenad Readers merging that we don't need as the indexer should have merged them and, therefore, we should only have one final grenad Reader. We reduce the amount of CPU usage and memory pressure we were doing uselessly.
`@ManyTheFish` are you sure I can skip merging the `word_docids` database?
Here is the benchmark comparison with the previously merged PR #454:
```
group indexing_reintroduce-appending-sorted-values_c05e42a8 indexing_remove-useless-grenad-merging_d5b8b5a2
----- ----------------------------------------------------- -----------------------------------------------
indexing/Indexing movies with default settings 1.06 16.6±1.04s ? ?/sec 1.00 15.7±0.93s ? ?/sec
indexing/Indexing songs with default settings 1.16 60.1±7.07s ? ?/sec 1.00 51.7±5.98s ? ?/sec
indexing/Indexing songs without faceted numbers 1.06 55.4±6.14s ? ?/sec 1.00 52.2±4.13s ? ?/sec
```
And the comparison with multi-batch indexing before #436, we can see that we gain time for benchmarks that index datasets in multiple batches but there is _so much_ variance that it's not clear.
```
group indexing_benchmark-multi-batch-indexing-before-speed-up_45f52620 indexing_remove-useless-grenad-merging_d5b8b5a2
----- ---------------------------------------------------------------- -----------------------------------------------
indexing/Indexing geo_point 1.07 6.6±0.08s ? ?/sec 1.00 6.2±0.11s ? ?/sec
indexing/Indexing songs in three batches with default settings 1.12 57.7±2.14s ? ?/sec 1.00 51.5±3.80s ? ?/sec
indexing/Indexing songs with default settings 1.00 47.5±2.52s ? ?/sec 1.09 51.7±5.98s ? ?/sec
indexing/Indexing songs without any facets 1.00 43.5±1.43s ? ?/sec 1.12 48.8±3.73s ? ?/sec
indexing/Indexing songs without faceted numbers 1.00 47.1±2.23s ? ?/sec 1.11 52.2±4.13s ? ?/sec
indexing/Indexing wiki 1.00 917.3±30.01s ? ?/sec 1.09 998.7±38.92s ? ?/sec
indexing/Indexing wiki in three batches 1.09 1091.2±32.73s ? ?/sec 1.00 996.5±15.70s ? ?/sec
```
What do you think `@irevoire?` Should we change the benchmarks to make them do more runs?
Co-authored-by: Kerollmops <clement@meilisearch.com>
454: Reintroduce appending sorted entries when possible r=Kerollmops a=Kerollmops
This PR modifies the `sorter_into_lmdb_database` function to append values into the database instead of get-put-merging them, it should improve the indexation speed for when the database is empty.
```txt
group indexing_main_25123af3 indexing_reintroduce-appending-sorted-values_c05e42a8
----- ---------------------- -----------------------------------------------------
indexing/Indexing movies with default settings 1.07 17.8±0.99s ? ?/sec 1.00 16.6±1.04s ? ?/sec
indexing/Indexing songs with default settings 1.00 57.0±6.01s ? ?/sec 1.05 60.1±7.07s ? ?/sec
indexing/Indexing songs without any facets 1.10 51.8±5.36s ? ?/sec 1.00 47.3±3.30s ? ?/sec
```
Co-authored-by: Clément Renault <clement@meilisearch.com>
453: Benchmark multi batch indexing r=Kerollmops a=Kerollmops
Hey `@irevoire,` could you please add the new benchmarks into influx?
Co-authored-by: Kerollmops <clement@meilisearch.com>
Co-authored-by: Clément Renault <clement@meilisearch.com>
436: Speed up the word prefix databases computation time r=Kerollmops a=Kerollmops
This PR depends on the fixes done in #431 and must be merged after it.
In this PR we will bring the `WordPrefixPairProximityDocids`, `WordPrefixDocids` and, `WordPrefixPositionDocids` update structures to a new era, a better era, where computing the word prefix pair proximities costs much fewer CPU cycles, an era where this update structure can use the, previously computed, set of new word docids from the newly indexed batch of documents.
---
The `WordPrefixPairProximityDocids` is an update structure, which means that it is an object that we feed with some parameters and which modifies the LMDB database of an index when asked for. This structure specifically computes the list of word prefix pair proximities, which correspond to a list of pairs of words associated with a proximity (the distance between both words) where the second word is not a word but a prefix e.g. `s`, `se`, `a`. This word prefix pair proximity is associated with the list of documents ids which contains the pair of words and prefix at the given proximity.
The origin of the performances issue that this struct brings is related to the fact that it starts its job from the beginning, it clears the LMDB database before rewriting everything from scratch, using the other LMDB databases to achieve that. I hope you understand that this is absolutely not an optimized way of doing things.
Co-authored-by: Clément Renault <clement@meilisearch.com>
Co-authored-by: Kerollmops <clement@meilisearch.com>
451: Update LICENSE with Meili SAS name r=Kerollmops a=curquiza
Check with thomas, we must put the real name of the company
Co-authored-by: Clémentine Urquizar - curqui <clementine@meilisearch.com>
450: Get rid of chrono in favor of time r=Kerollmops a=irevoire
We only use `chrono` as a wrapper around `time`, and since there has been an [open CVE on `chrono` for at least 3 months now](https://github.com/chronotope/chrono/pull/632) and the repo seems to be [struggling with maintenance](https://github.com/chronotope/chrono/pull/639), I think we should use `time` directly which is way more active and sufficient for our use case.
EDIT: Actually the CVE status has been known for more than 6 months: https://github.com/chronotope/chrono/issues/602
Co-authored-by: Irevoire <tamo@meilisearch.com>
442: fix phrase search r=curquiza a=MarinPostma
Run the exact match search on 7 words windows instead of only two. This makes false positive very very unlikely, and impossible on phrase query that are less than seven words.
Co-authored-by: ad hoc <postma.marin@protonmail.com>
445: allow null values in csv r=Kerollmops a=MarinPostma
This pr allows null values in csv:
- if the field is of type string, then an empty field is considered null (`,,`), anything other is turned into a string (i.e `, ,` is a single whitespace string)
- if the field is of type number, when the trimmed field is empty, we consider the value null (i.e `,,`, `, ,` are both null numbers) otherwise we try to parse the number.
Co-authored-by: ad hoc <postma.marin@protonmail.com>
417: Change chunk size to 4MiB to fit more the end user usage r=Kerollmops a=ManyTheFish
Reverts meilisearch/milli#379
We made several indexing tests using different sizes of datasets (5 datasets from 9MiB to 100MiB) on several typologies of VMs (`XS: 1GiB RAM, 1 VCPU`, `S: 2GiB RAM, 2 VCPU`, `M: 4GiB RAM, 3 VCPU`, `L: 8GiB RAM, 4 VCPU`).
The result of these tests shows that the `4MiB` chunk size seems to be the best size compared to other chunk sizes (`2Mib`, `4MiB`, `8Mib`, `16Mib`, `32Mib`, `64Mib`, `128Mib`).
below is the average time per chunk size:

<details>
<summary>Detailled data</summary>
<br>
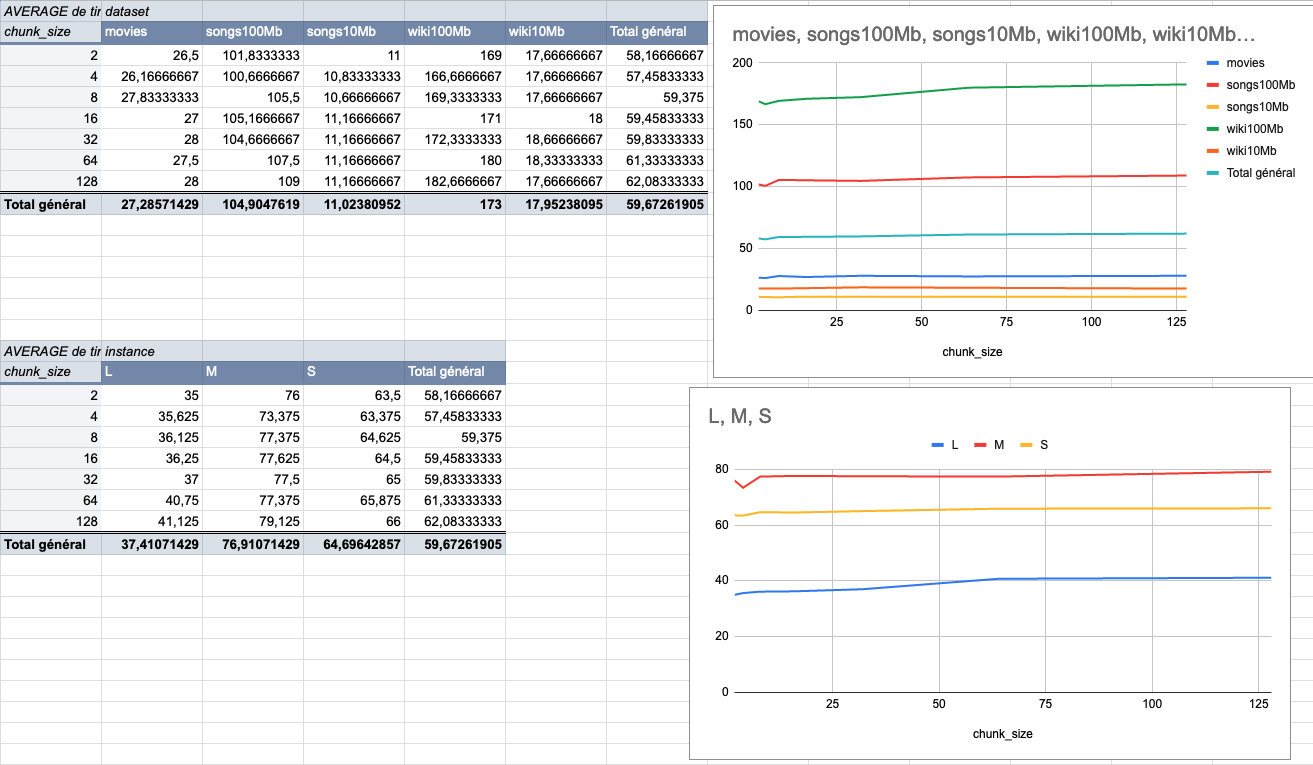
</br>
</details>
Co-authored-by: Many <many@meilisearch.com>
444: Fix the parsing of ndjson requests to index more than the first line r=Kerollmops a=Kerollmops
This PR correctly uses the `BufRead` trait to read every line of the content instead of just the first one. This bug was only affecting the http-ui test crate.
Co-authored-by: Kerollmops <clement@meilisearch.com>
{kind=link}
{kind=link}