Instead of using an arbitrary limit we encode the absolute position in a u32
using one strong u16 for the field id and a weak u16 for the relative position in the attribute.
386: fix obkv document r=curquiza a=MarinPostma
When serializing a document, the serializer resolved the field_id of the current field and immediately added it to the obkv document under construction. The issue with that is that obkv expects the fields to be inserted in order, and when a document with out of order fields was added, obkv failed to insert the field.
The current fix first resolves each field_id, and adds all the fields to a temporary `BTreeMap`, until `end` is called on the map serializer, where all the fields are added to the obkv at once, and in order.
Co-authored-by: mpostma <postma.marin@protonmail.com>
383: Add check on latitude and longitude r=irevoire a=irevoire
Latitudes are not supposed to go beyond 90 degrees or below -90.
The same goes for longitudes with 180 or -180.
This was badly implemented in the filters, and was not implemented for the `AscDesc` rules.
Co-authored-by: Tamo <tamo@meilisearch.com>
Co-authored-by: Irevoire <tamo@meilisearch.com>
Latitude are not supposed to go beyound 90 degrees or below -90.
The same goes for longitude with 180 or -180.
This was badly implemented in the filters, and was not implemented for the AscDesc rules.
380: Reserved keyword error message r=Kerollmops a=irevoire
And I missed _another_ reserved keyword error message in the filter :(
Co-authored-by: Tamo <tamo@meilisearch.com>
379: Revert "Change chunk size to 4MiB to fit more the end user usage" r=curquiza a=ManyTheFish
Reverts meilisearch/milli#370
Co-authored-by: Many <legendre.maxime.isn@gmail.com>
378: Hotfix meilisearch#1707 r=Kerollmops a=ManyTheFish
This PR contains an ugly quick fix of [meilisearch#1707](https://github.com/meilisearch/MeiliSearch/issues/1707).
- remove comparison reverse on rank. Enhancing relevancy and performances
- iterate over level 0 only. Enhancing performances.
A better fix is in development.
Co-authored-by: many <maxime@meilisearch.com>
Co-authored-by: Many <legendre.maxime.isn@gmail.com>
374: Enhance CSV document parsing r=Kerollmops a=ManyTheFish
Benchmarks on `search_songs` were crashing because of the CSV parsing.
Co-authored-by: many <maxime@meilisearch.com>
376: Stop casting integer docids to string r=Kerollmops a=irevoire
When a docid is an integer, we stop casting it to a string, and thus we don't add `"` around it.
Co-authored-by: Tamo <tamo@meilisearch.com>
373: Improve error message for bad sort syntax with geosearch r=Kerollmops a=irevoire
`@Kerollmops` This should be the last PR for the geosearch and error handling, sorry for doing it in so many steps 😬
Co-authored-by: Tamo <tamo@meilisearch.com>
372: Fix Meilisearch 1714 r=Kerollmops a=ManyTheFish
The bug comes from the typo tolerance, to know how many typos are accepted we were counting bytes instead of characters in a word.
On Chinese Script characters, we were allowing 2 typos on 3 characters words.
We are now counting the number of char instead of counting bytes to assign the typo tolerance.
Related to [Meilisearch#1714](https://github.com/meilisearch/MeiliSearch/issues/1714)
Co-authored-by: many <maxime@meilisearch.com>
371: Provide a sort error handler r=Kerollmops a=irevoire
This PR simplify the error handling of asc-desc rules for Meilisearch or any other wrapper by providing directly in milli a new error type called `SortError` that can be generated from an `AscDescError` and that can be automatically converted to a `UserError`.
Basically now, wherever you are in the code as a user or in milli you can parse an `AscDesc` syntax and depending on the context, cast it either as a `SortError` or a `CriterionError` in one line with improved error messages.
Co-authored-by: Tamo <tamo@meilisearch.com>
370: Change chunk size to 4MiB to fit more the end user usage r=ManyTheFish a=ManyTheFish
We made several indexing tests using different sizes of datasets (5 datasets from 9MiB to 100MiB) on several typologies of VMs (`XS: 1GiB RAM, 1 VCPU`, `S: 2GiB RAM, 2 VCPU`, `M: 4GiB RAM, 3 VCPU`, `L: 8GiB RAM, 4 VCPU`).
The result of these tests shows that the `4MiB` chunk size seems to be the best size compared to other chunk sizes (`2Mib`, `4MiB`, `8Mib`, `16Mib`, `32Mib`, `64Mib`, `128Mib`).
below is the average time per chunk size:

<details>
<summary>Detailled data</summary>
<br>
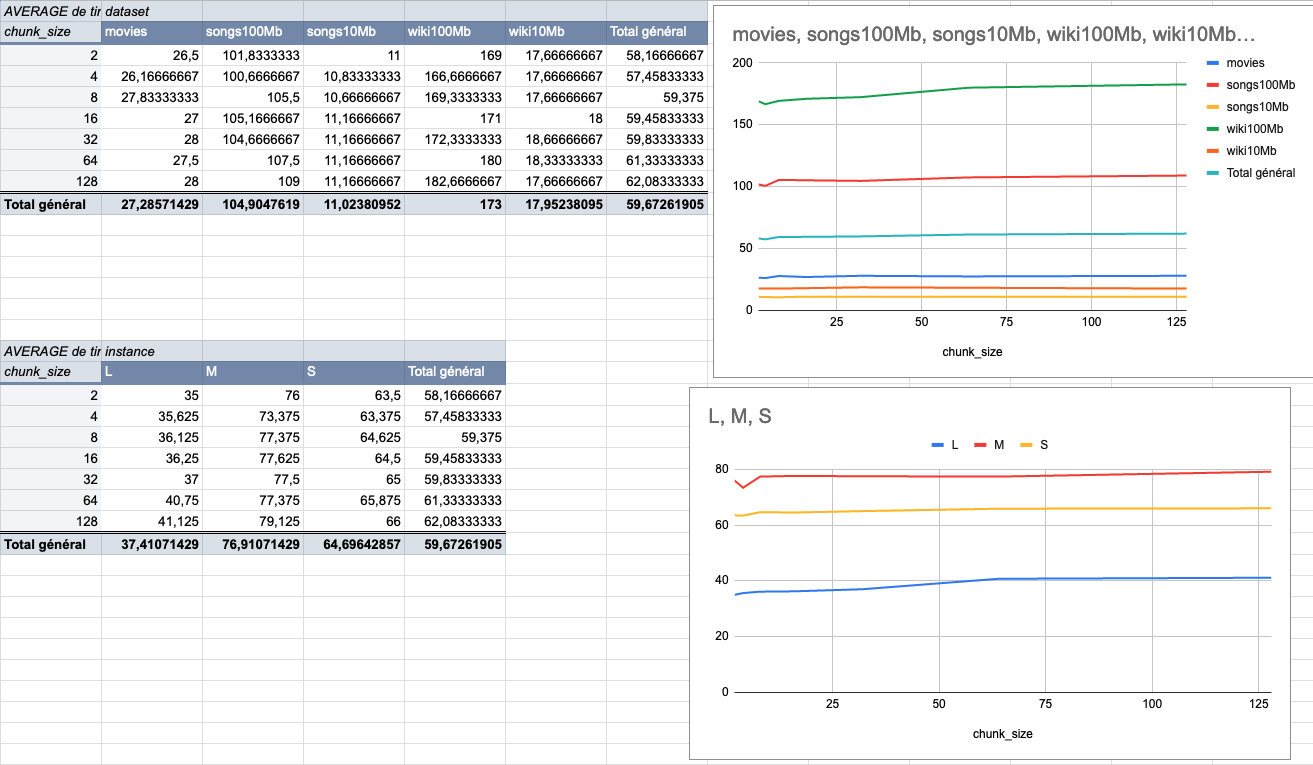
</br>
</details>
Co-authored-by: many <maxime@meilisearch.com>
369: Add test checking the bug reported in meilisearch issue 1716 r=Kerollmops a=ManyTheFish
The bug is not present in the newer milli version.
Related to [Meilisearch#1716](https://github.com/meilisearch/MeiliSearch/issues/1716)
Co-authored-by: many <maxime@meilisearch.com>
{kind=link}
{kind=link}