168 KiB
Vendored
![]()
![]()
What the f*ck Python! 😱
Изучение и понимание Python с помощью нестандартного поведения и "магического" поведения.
Переводы: English Original Chinese 中文 | Vietnamese Tiếng Việt | Spanish Español | Korean 한국어 | Russian Русский | German Deutsch | Add translation
Альтернативные способы: Интерактивный сайт | Интерактивный Jupiter notebook | CLI
Python, будучи прекрасно спроектированным высокоуровневым языком программирования, предоставляет множество возможностей для удобства программиста. Но иногда результаты работы Python кода могут показаться неочевидными на первый взгляд.
wtfpython задуман как проект, пытающийся объяснить, что именно происходит под капотом некоторых неочевидных фрагментов кода и менее известных возможностей Python.
Если вы опытный программист на Python, вы можете принять это как вызов и правильно объяснить WTF ситуации с первой попытки. Возможно, вы уже сталкивались с некоторыми из них раньше, и я смогу оживить ваши старые добрые воспоминания! 😅
PS: Если вы уже читали wtfpython раньше, с изменениями можно ознакомиться здесь (примеры, отмеченные звездочкой - это примеры, добавленные в последней основной редакции).
Ну что ж, приступим...
Содержание
Структура примера
Все примеры имеют следующую структуру:
▶ Какой-то заголовок
# Неочевидный фрагмент кода # Подготовка к магии...Вывод (Python версия):
>>> triggering_statement Неожиданные результаты(Опционально): Краткое описание неожиданного результата
💡 Объяснение
- Краткое объяснение того, что происходит и почему это происходит.
# Код # Дополнительные примеры для дальнейшего разъяснения (если необходимо)Вывод (Python версия):
>>> trigger # какой-нибудь пример, позволяющий легко раскрыть магию # обоснованный вывод
Важно: Все примеры протестированы на интерактивном интерпретаторе Python 3.5.2, и они должны работать для всех версий Python, если это явно не указано перед выводом.
Применение
Хороший способ получить максимальную пользу от этих примеров - читать их последовательно, причем для каждого из них важно:
- Внимательно изучить исходный код. Если вы опытный программист на Python, то в большинстве случаев сможете предугадать, что произойдет дальше.
- Прочитать фрагменты вывода и,
- Проверить, совпадают ли выходные данные с вашими ожиданиями.
- Убедиться, что вы знаете точную причину, по которой вывод получился именно таким.
- Если ответ отрицательный (что совершенно нормально), сделать глубокий вдох и прочитать объяснение (а если пример все еще непонятен, и создайте issue здесь).
- Если "да", ощутите мощь своих познаний в Python и переходите к следующему примеру.
PS: Вы также можете читать WTFPython в командной строке, используя pypi package,
pip install wtfpython -U
wtfpython
👀 Примеры
Секция: Напряги мозги!
▶ Первым делом!
По какой-то причине "моржовый оператор" (англ. walrus) := в Python 3.8 стал довольно популярным. Давайте проверим его,
1.
# Python version 3.8+
>>> a = "wtf_walrus"
>>> a
'wtf_walrus'
>>> a := "wtf_walrus"
File "<stdin>", line 1
a := "wtf_walrus"
^
SyntaxError: invalid syntax
>>> (a := "wtf_walrus") # А этот код работает
'wtf_walrus'
>>> a
'wtf_walrus'
2 .
# Python version 3.8+
>>> a = 6, 9
>>> a
(6, 9)
>>> (a := 6, 9)
(6, 9)
>>> a
6
>>> a, b = 6, 9 # Типичная распаковка
>>> a, b
(6, 9)
>>> (a, b = 16, 19) # Упс
File "<stdin>", line 1
(a, b = 16, 19)
^
SyntaxError: invalid syntax
>>> (a, b := 16, 19) # На выводе получаем странный кортеж из 3 элементов
(6, 16, 19)
>>> a # Значение переменной остается неизменной?
6
>>> b
16
💡 Обьяснение
Быстрый разбор что такое "моржовый оператор"
"Моржовый оператор" (:=) был представлен в Python 3.8, может быть полезен в ситуациях, когда вы хотите присвоить значения переменным в выражении.
def some_func():
# Предположим, что здесь выполняются требовательные к ресурсам вычисления
# time.sleep(1000)
return 5
# Поэтому вместо,
if some_func():
print(some_func()) # Плохая практика, поскольку вычисления происходят дважды.
# Или
a = some_func()
if a:
print(a)
# Можно лаконично написать
if a := some_func():
print(a)
Вывод (> 3.8):
5
5
5
Использование := сэкономило одну строку кода и неявно предотвратило вызов some_func дважды.
-
"выражение присваивания", не обернутое в скобки, иначе говоря использование моржового оператора, ограничено на верхнем уровне, отсюда
SyntaxErrorв выраженииa := "wtf_walrus"в первом фрагменте. После оборачивания в скобки,aбыло присвоено значение, как и ожидалось. -
В то же время оборачивание скобками выражения, содержащего оператор
=, не допускается. Отсюда синтаксическая ошибка в(a, b = 6, 9). -
Синтаксис моржового оператора имеет вид
NAME:= expr, гдеNAME- допустимый идентификатор, аexpr- допустимое выражение. Следовательно, упаковка и распаковка итерируемых объектов не поддерживается, что означает,-
(a := 6, 9)эквивалентно((a := 6), 9)и в конечном итоге(a, 9)(где значениеaравно6)>>> (a := 6, 9) == ((a := 6), 9) True >>> x = (a := 696, 9) >>> x (696, 9) >>> x[0] is a # Оба ссылаются на одну и ту же ячейку памяти True -
Аналогично,
(a, b := 16, 19)эквивалентно(a, (b := 16), 19), которое есть не что иное, как кортеж из 3 элементов.
-
▶ Строки иногда ведут себя непредсказуемо
1.
>>> a = "some_string"
>>> id(a)
140420665652016
>>> id("some" + "_" + "string") # Обратите внимание, оба идентификатора одинаковы
140420665652016
2.
>>> a = "wtf"
>>> b = "wtf"
>>> a is b
True
>>> a = "wtf!"
>>> b = "wtf!"
>>> a is b
False
3.
>>> a, b = "wtf!", "wtf!"
>>> a is b # Актуально для версий Python, кроме 3.7.x
True
>>> a = "wtf!"; b = "wtf!"
>>> a is b # Выражение вернет True или False в зависимости вызываемой среды (python shell / ipython / скрипт).
False
# На этот раз в файле
a = "wtf!"
b = "wtf!"
print(a is b)
# Выводит True при запуске модуля
4.
Output (< Python3.7 )
>>> 'a' * 20 is 'aaaaaaaaaaaaaaaaaaaa'
True
>>> 'a' * 21 is 'aaaaaaaaaaaaaaaaaaaaa'
False
Логично, правда?
💡 Объяснение
- Поведение в первом и втором фрагментах связано с оптимизацией CPython (называемой интернированием строк ((англ. string interning))), которая пытается использовать существующие неизменяемые объекты в некоторых случаях вместо того, чтобы каждый раз создавать новый объект.
- После "интернирования" многие переменные могут ссылаться на один и тот же строковый объект в памяти (тем самым экономя память).
- В приведенных выше фрагментах строки неявно интернированы. Решение о том, когда неявно интернировать строку, зависит от реализации. Правила для интернирования строк следующие:
- Все строки длиной 0 или 1 символа интернируются.
- Строки интернируются во время компиляции (
'wtf'будет интернирована, но''.join(['w'', 't', 'f'])- нет) - Строки, не состоящие из букв ASCII, цифр или знаков подчеркивания, не интернируются. В примере выше
'wtf!'не интернируется из-за!. Реализацию этого правила в CPython можно найти здесь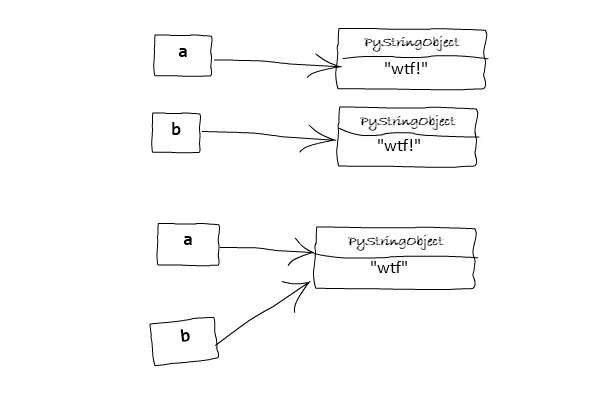
- Когда переменные
aиbпринимают значение"wtf!"в одной строке, интерпретатор Python создает новый объект, а затем одновременно ссылается на вторую переменную. Если это выполняется в отдельных строках, он не "знает", что уже существует"wtf!"как объект (потому что"wtf!"не является неявно интернированным в соответствии с фактами, упомянутыми выше). Это оптимизация во время компиляции, не применяется к версиям CPython 3.7.x (более подробное обсуждение смотрите здесь issue). - Единица компиляции в интерактивной среде IPython состоит из одного оператора, тогда как в случае модулей она состоит из всего модуля.
a, b = "wtf!", "wtf!"- это одно утверждение, тогда какa = "wtf!"; b = "wtf!"- это два утверждения в одной строке. Это объясняет, почему тождества различны вa = "wtf!"; b = "wtf!", но одинаковы при вызове в модуле. - Резкое изменение в выводе четвертого фрагмента связано с peephole optimization техникой, известной как складывание констант (англ. Constant folding). Это означает, что выражение
'a'*20заменяется на'aaaaaaaaaaaaaaaaaaaa'во время компиляции, чтобы сэкономить несколько тактов во время выполнения. Складывание констант происходит только для строк длиной менее 21. (Почему? Представьте себе размер файла.pyc, созданного в результате выполнения выражения'a'*10**10). Вот исходный текст реализации для этого. - Примечание: В Python 3.7 складывание констант было перенесено из оптимизатора peephole в новый оптимизатор AST с некоторыми изменениями в логике, поэтому четвертый фрагмент не работает в Python 3.7. Подробнее об изменении можно прочитать здесь.
▶ Осторожнее с цепочкой операций
>>> (False == False) in [False] # логично
False
>>> False == (False in [False]) # все еще логично
False
>>> False == False in [False] # а теперь что?
True
>>> True is False == False
False
>>> False is False is False
True
>>> 1 > 0 < 1
True
>>> (1 > 0) < 1
False
>>> 1 > (0 < 1)
False
💡 Объяснение:
Согласно https://docs.python.org/3/reference/expressions.html#comparisons
Формально, если a, b, c, ..., y, z - выражения, а op1, op2, ..., opN - операторы сравнения, то a op1 b op2 c ... y opN z эквивалентно a op1 b и b op2 c и ... y opN z, за исключением того, что каждое выражение оценивается не более одного раза.
Хотя такое поведение может показаться глупым в приведенных выше примерах, оно просто фантастично для таких вещей, как a == b == c и 0 <= x <= 100.
False is False is Falseэквивалентно(False is False) и (False is False).True is False == Falseэквивалентно(True is False) and (False == False)и так как первая часть высказывания (True is False) оценивается вFalse, то все выражение приводится кFalse.1 > 0 < 1эквивалентно(1 > 0) и (0 < 1), которое приводится кTrue.- Выражение
(1 > 0) < 1эквивалентноTrue < 1и
В итоге,>>> int(True) 1 >>> True + 1 # не относится к данному примеру, но просто для интереса 21 < 1выполняется и дает результатFalse
▶ Как не надо использовать оператор is
Ниже приведен очень известный пример.
1.
>>> a = 256
>>> b = 256
>>> a is b
True
>>> a = 257
>>> b = 257
>>> a is b
False
2.
>>> a = []
>>> b = []
>>> a is b
False
>>> a = tuple()
>>> b = tuple()
>>> a is b
True
3. Результат
>>> a, b = 257, 257
>>> a is b
True
Вывод (только для Python 3.7.x)
>>> a, b = 257, 257
>>> a is b
False
💡 Объяснение:
Разница между is и ==.
- Оператор
isпроверяет, ссылаются ли оба операнда на один и тот же объект (т.е. проверяет, совпадают ли идентификаторы операндов или нет). - Оператор
==сравнивает значения обоих операндов и проверяет, одинаковы ли они. - Таким образом, оператор
isпредназначен для равенства ссылок, а==- для равенства значений. Пример, чтобы прояснить ситуацию,>>> class A: pass >>> A() is A() # 2 пустых объекта в разных ячейках памяти False
256 - существующий объект, а 257 - нет.
При запуске python числа от -5 до 256 записываются в память. Эти числа используются часто, поэтому имеет смысл просто иметь их наготове.
Перевод цитаты из документации
Текущая реализация хранит массив целочисленных объектов для всех целых чисел от -5 до 256, когда вы создаете int в этом диапазоне, вы просто получаете обратно ссылку на существующий объект.
>>> id(256)
10922528
>>> a = 256
>>> b = 256
>>> id(a)
10922528
>>> id(b)
10922528
>>> id(257)
140084850247312
>>> x = 257
>>> y = 257
>>> id(x)
140084850247440
>>> id(y)
140084850247344
Интерпретатор не понимает, что до выполнения выражения y = 257 целое число со значением 257 уже создано, и поэтому он продолжает создавать другой объект в памяти.
Подобная оптимизация применима и к другим изменяемым объектам, таким как пустые кортежи. Поскольку списки являются изменяемыми, поэтому [] is [] вернет False, а () is () вернет True. Это объясняет наш второй фрагмент. Перейдем к третьему,
И a, и b ссылаются на один и тот же объект при инициализации одним и тем же значением в одной и той же строкеi.
Вывод
>>> a, b = 257, 257
>>> id(a)
140640774013296
>>> id(b)
140640774013296
>>> a = 257
>>> b = 257
>>> id(a)
140640774013392
>>> id(b)
140640774013488
-
Когда a и b инициализируются со значением
257в одной строке, интерпретатор Python создает новый объект, а затем одновременно ссылается на него во второй переменной. Если делать это в отдельных строках, интерпретатор не "знает", что объект257уже существует. -
Это оптимизация компилятора и относится именно к интерактивной среде. Когда вы вводите две строки в интерпретаторе, они компилируются отдельно, поэтому оптимизируются отдельно. Если выполнить этот пример в файле `.py', поведение будет отличаться, потому что файл компилируется весь сразу. Эта оптимизация не ограничивается целыми числами, она работает и для других неизменяемых типов данных, таких как строки (проверьте пример "Строки - это сложно") и плавающие числа,
>>> a, b = 257.0, 257.0 >>> a is b True -
Почему это не сработало в Python 3.7? Абстрактная причина в том, что такие оптимизации компилятора зависят от реализации (т.е. могут меняться в зависимости от версии, ОС и т.д.). Я все еще выясняю, какое именно изменение реализации вызвало проблему, вы можете проверить этот issue для получения обновлений.
▶ Мистическое хэширование
1.
some_dict = {}
some_dict[5.5] = "JavaScript"
some_dict[5.0] = "Ruby"
some_dict[5] = "Python"
Вывод:
>>> some_dict[5.5]
"JavaScript"
>>> some_dict[5.0] # "Python" уничтожил "Ruby"?
"Python"
>>> some_dict[5]
"Python"
>>> complex_five = 5 + 0j
>>> type(complex_five)
complex
>>> some_dict[complex_five]
"Python"
Так почему же Python повсюду?
💡 Объяснение
-
Уникальность ключей в словаре Python определяется эквивалентностью, а не тождеством. Поэтому, даже если
5,5.0и5 + 0jявляются различными объектами разных типов, поскольку они равны, они не могут находиться в одном и том жеdict(илиset). Как только вы вставите любой из них, попытка поиска по любому другому, но эквивалентному ключу будет успешной с исходным сопоставленным значением (а не завершится ошибкойKeyError):>>> 5 == 5.0 == 5 + 0j True >>> 5 is not 5.0 is not 5 + 0j True >>> some_dict = {} >>> some_dict[5.0] = "Ruby" >>> 5.0 in some_dict True >>> (5 in some_dict) and (5 + 0j in some_dict) True -
Это применимо и во время присваения значения элементу. Поэтому, в выражении
some_dict[5] = "Python"Python находит существующий элемент с эквивалентным ключом5.0 -> "Ruby", перезаписывает его значение на место, а исходный ключ оставляет в покое.>>> some_dict {5.0: 'Ruby'} >>> some_dict[5] = "Python" >>> some_dict {5.0: 'Python'} -
Итак, как мы можем обновить ключ до
5(вместо5.0)? На самом деле мы не можем сделать это обновление на месте, но что мы можем сделать, так это сначала удалить ключ (del some_dict[5.0]), а затем установить его (some_dict[5]), чтобы получить целое число5в качестве ключа вместо плавающего5.0, хотя это нужно в редких случаях. -
Как Python нашел
5в словаре, содержащем5.0? Python делает это за постоянное время без необходимости сканирования каждого элемента, используя хэш-функции. Когда Python ищет ключfooв словаре, он сначала вычисляетhash(foo)(что выполняется в постоянном времени). Поскольку в Python требуется, чтобы объекты, которые сравниваются одинаково, имели одинаковое хэш-значение (docs здесь),5,5.0и5 + 0jимеют одинаковое хэш-значение.>>> 5 == 5.0 == 5 + 0j True >>> hash(5) == hash(5.0) == hash(5 + 0j) TrueПримечание: Обратное не обязательно верно: Объекты с одинаковыми хэш-значениями сами могут быть неравными. (Это вызывает так называемую хэш-коллизию и ухудшает производительность постоянного времени, которую обычно обеспечивает хэширование).
▶ В глубине души мы все одинаковы.
class WTF:
pass
Вывод:
>>> WTF() == WTF() # разные экземпляры класса не могут быть равны
False
>>> WTF() is WTF() # идентификаторы также различаются
False
>>> hash(WTF()) == hash(WTF()) # хэши тоже должны отличаться
True
>>> id(WTF()) == id(WTF())
True
💡 Объяснение:
-
При вызове
idPython создал объект классаWTFи передал его функцииid. Функцияidзабирает свойid(местоположение в памяти) и выбрасывает объект. Объект уничтожается. -
Когда мы делаем это дважды подряд, Python выделяет ту же самую область памяти и для второго объекта. Поскольку (в CPython)
idиспользует участок памяти в качестве идентификатора объекта, идентификатор двух объектов одинаков. -
Таким образом, id объекта уникален только во время жизни объекта. После уничтожения объекта или до его создания, другой объект может иметь такой же id.
-
Но почему выражение с оператором
isравноFalse? Давайте посмотрим с помощью этого фрагмента.class WTF(object): def __init__(self): print("I") def __del__(self): print("D")Вывод:
>>> WTF() is WTF() I I D D False >>> id(WTF()) == id(WTF()) I D I D TrueКак вы можете заметить, все дело в порядке уничтожения объектов.
▶ Беспорядок внутри порядка *
from collections import OrderedDict
dictionary = dict()
dictionary[1] = 'a'; dictionary[2] = 'b';
ordered_dict = OrderedDict()
ordered_dict[1] = 'a'; ordered_dict[2] = 'b';
another_ordered_dict = OrderedDict()
another_ordered_dict[2] = 'b'; another_ordered_dict[1] = 'a';
class DictWithHash(dict):
"""
A dict that also implements __hash__ magic.
"""
__hash__ = lambda self: 0
class OrderedDictWithHash(OrderedDict):
"""
An OrderedDict that also implements __hash__ magic.
"""
__hash__ = lambda self: 0
Вывод
>>> dictionary == ordered_dict # a == b
True
>>> dictionary == another_ordered_dict # b == c
True
>>> ordered_dict == another_ordered_dict # почему же c != a ??
False
# Мы все знаем, что множество состоит только из уникальных элементов,
# давайте попробуем составить множество из этих словарей и посмотрим, что получится...
>>> len({dictionary, ordered_dict, another_ordered_dict})
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'dict'
# Логично, поскольку в словаре не реализовано магический метод __hash__, попробуем использовать
# наши классы-обертки.
>>> dictionary = DictWithHash()
>>> dictionary[1] = 'a'; dictionary[2] = 'b';
>>> ordered_dict = OrderedDictWithHash()
>>> ordered_dict[1] = 'a'; ordered_dict[2] = 'b';
>>> another_ordered_dict = OrderedDictWithHash()
>>> another_ordered_dict[2] = 'b'; another_ordered_dict[1] = 'a';
>>> len({dictionary, ordered_dict, another_ordered_dict})
1
>>> len({ordered_dict, another_ordered_dict, dictionary}) # changing the order
2
Что здесь происходит?
💡 Объяснение:
-
Переходное (интрантизивное) равенство между
dictionary,ordered_dictиanother_ordered_dictне выполняется из-за реализации магического метода__eq__в классеOrderedDict. Перевод цитаты из документацииТесты равенства между объектами OrderedDict чувствительны к порядку и реализуются как
list(od1.items())==list(od2.items()). Тесты на равенство между объектамиOrderedDictи другими объектами Mapping нечувствительны к порядку, как обычные словари. -
Причина такого поведения равенства в том, что оно позволяет напрямую подставлять объекты
OrderedDictвезде, где используется обычный словарь. -
Итак, почему изменение порядка влияет на длину генерируемого объекта
set? Ответ заключается только в отсутствии переходного равенства. Поскольку множества являются "неупорядоченными" коллекциями уникальных элементов, порядок вставки элементов не должен иметь значения. Но в данном случае он имеет значение. Давайте немного разберемся в этом,>>> some_set = set() >>> some_set.add(dictionary) # используем объекты из фрагмента кода выше >>> ordered_dict in some_set True >>> some_set.add(ordered_dict) >>> len(some_set) 1 >>> another_ordered_dict in some_set True >>> some_set.add(another_ordered_dict) >>> len(some_set) 1 >>> another_set = set() >>> another_set.add(ordered_dict) >>> another_ordered_dict in another_set False >>> another_set.add(another_ordered_dict) >>> len(another_set) 2 >>> dictionary in another_set True >>> another_set.add(another_ordered_dict) >>> len(another_set) 2Таким образом, выражение
another_ordered_dictвanother_setравноFalse, потому чтоordered_dictуже присутствовал вanother_setи, как было замечено ранее,ordered_dict == another_ordered_dictравноFalse.
▶ Продолжай пытаться... *
def some_func():
try:
return 'from_try'
finally:
return 'from_finally'
def another_func():
for _ in range(3):
try:
continue
finally:
print("Finally!")
def one_more_func(): # Попался!
try:
for i in range(3):
try:
1 / i
except ZeroDivisionError:
# Вызовем исключение и обработаем его за пределами цикла
raise ZeroDivisionError("A trivial divide by zero error")
finally:
print("Iteration", i)
break
except ZeroDivisionError as e:
print("Zero division error occurred", e)
Результат:
>>> some_func()
'from_finally'
>>> another_func()
Finally!
Finally!
Finally!
>>> 1 / 0
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ZeroDivisionError: division by zero
>>> one_more_func()
Iteration 0
💡 Объяснение:
- Когда один из операторов
return,breakилиcontinueвыполняется в блокеtryоператора "try...finally", на выходе также выполняется пунктfinally. - Возвращаемое значение функции определяется последним выполненным оператором
return. Поскольку блокfinallyвыполняется всегда, операторreturn, выполненный в блокеfinally, всегда будет последним. - Предостережение - если в блоке
finallyвыполняется операторreturnилиbreak, то временно сохраненное исключение отбрасывается.
▶ Для чего?
some_string = "wtf"
some_dict = {}
for i, some_dict[i] in enumerate(some_string):
i = 10
Вывод:
>>> some_dict # Словарь с индексами
{0: 'w', 1: 't', 2: 'f'}
💡 Объяснение:
-
Оператор
forопределяется в грамматике Python как:for_stmt: 'for' exprlist 'in' testlist ':' suite ['else' ':' suite]Где
exprlist- цель присваивания. Это означает, что эквивалент{exprlist} = {next_value}выполняется для каждого элемента в итерируемом объекте. Интересный пример, иллюстрирующий это:for i in range(4): print(i) i = 10Результат:
0 1 2 3Не ожидали, что цикл будет запущен только один раз?
💡 Объяснение:.
- Оператор присваивания
i = 10никогда не влияет на итерации цикла из-за того, как циклы for работают в Python. Перед началом каждой итерации следующий элемент, предоставляемый итератором (в данном случаеrange(4)), распаковывается и присваивается переменной целевого списка (в данном случаеi).
- Оператор присваивания
-
Функция
enumerate(some_string)на каждой итерации выдает новое значениеi(счетчик-инкремент) и символ изsome_string. Затем она устанавливает (только что присвоенный) ключiсловаряsome_dictна этот символ. Развертывание цикла можно упростить следующим образом:>>> i, some_dict[i] = (0, 'w') >>> i, some_dict[i] = (1, 't') >>> i, some_dict[i] = (2, 'f') >>> some_dict
▶ Расхождение во времени исполнения
1.
array = [1, 8, 15]
# Типичный генератор
gen = (x for x in array if array.count(x) > 0)
array = [2, 8, 22]
Вывод:
>>> print(list(gen)) # Куда подевались остальные значения?
[8]
2.
array_1 = [1,2,3,4]
gen_1 = (x for x in array_1)
array_1 = [1,2,3,4,5]
array_2 = [1,2,3,4]
gen_2 = (x for x in array_2)
array_2[:] = [1,2,3,4,5]
Вывод:
>>> print(list(gen_1))
[1, 2, 3, 4]
>>> print(list(gen_2))
[1, 2, 3, 4, 5]
3.
array_3 = [1, 2, 3]
array_4 = [10, 20, 30]
gen = (i + j for i in array_3 for j in array_4)
array_3 = [4, 5, 6]
array_4 = [400, 500, 600]
Вывод:
>>> print(list(gen))
[401, 501, 601, 402, 502, 602, 403, 503, 603]
💡 Объяснение
-
В выражении генераторе условие
inоценивается во время объявления, но условиеifоценивается во время выполнения. -
Перед выполнением кода, значение переменной
arrayизменяется на список[2, 8, 22], а поскольку из1,8и15только счетчик8больше0, генератор выдает только8. -
Различия в выводе
g1иg2во второй части связаны с тем, как переменнымarray_1иarray_2присваиваются новые значения.- В первом случае
array_1привязывается к новому объекту[1,2,3,4,5], а посколькуinвыражение исполняется во время объявления, оно по-прежнему ссылается на старый объект[1,2,3,4](который не уничтожается). - Во втором случае присвоение среза
array_2обновляет тот же старый объект[1,2,3,4]до[1,2,3,4,5]. Следовательно, иg2, иarray_2по-прежнему имеют ссылку на один и тот же объект (который теперь обновлен до[1,2,3,4,5]).
- В первом случае
-
Хорошо, следуя приведенной выше логике, не должно ли значение
list(gen)в третьем фрагменте быть[11, 21, 31, 12, 22, 32, 13, 23, 33]? (потому чтоarray_3иarray_4будут вести себя так же, какarray_1). Причина, по которой (только) значенияarray_4обновляются, объясняется в PEP-289Только крайнее for-выражение исполняется немедленно, остальные выражения откладываются до запуска генератора.
▶ is not ... не является is (not ...)
>>> 'something' is not None
True
>>> 'something' is (not None)
False
💡 Объяснение
is notявляется единым бинарным оператором, и его поведение отличается от раздельного использованияisиnot.is notимеет значениеFalse, если переменные по обе стороны оператора указывают на один и тот же объект, иTrueв противном случае.- В примере
(not None)оценивается вTrue, поскольку значениеNoneявляетсяFalseв булевом контексте, поэтому выражение становится'something' is True.
▶ Крестики-нолики, где X побеждает с первой попытки!
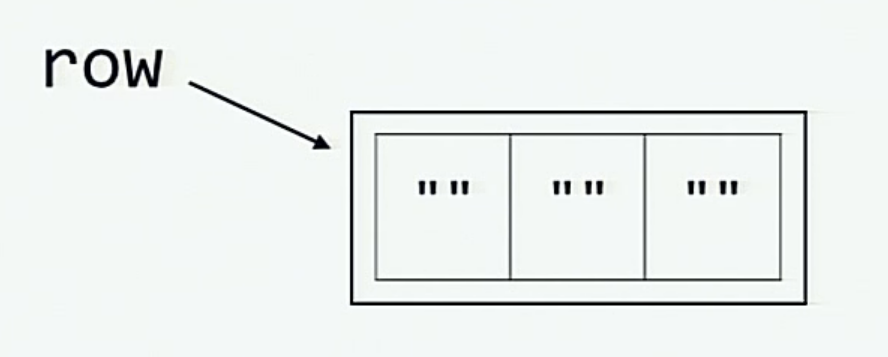
# Инициализируем переменную row
row = [""] * 3 #row i['', '', '']
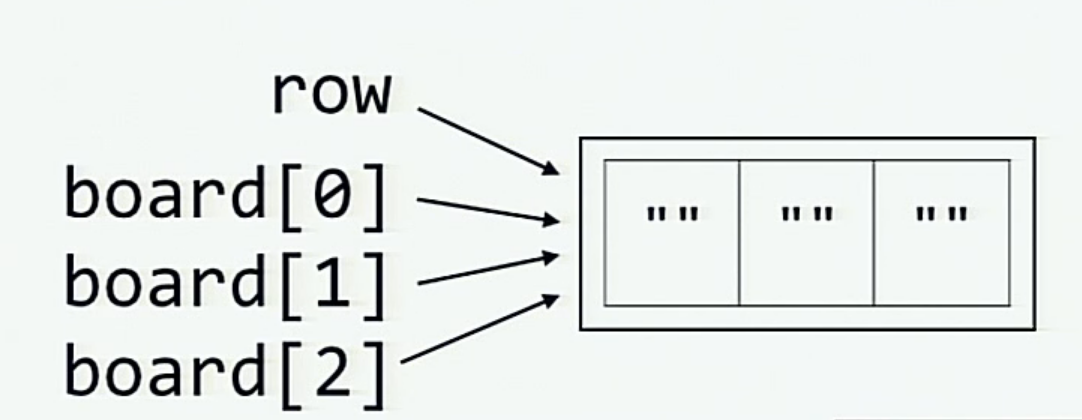
# Инициализируем игровую сетку
board = [row] * 3
Результат:
>>> board
[['', '', ''], ['', '', ''], ['', '', '']]
>>> board[0]
['', '', '']
>>> board[0][0]
''
>>> board[0][0] = "X"
>>> board
[['X', '', ''], ['X', '', ''], ['X', '', '']]
Мы же не назначили три "Х"?
💡 Объяснение:
Когда мы инициализируем переменную row, эта визуализация объясняет, что происходит в памяти
А когда переменная board инициализируется путем умножения row, вот что происходит в памяти (каждый из элементов board[0], board[1] и board[2] является ссылкой на тот же список, на который ссылается row)
Мы можем избежать этого сценария, не используя переменную row для генерации board. (Подробнее в issue).
>>> board = [['']*3 for _ in range(3)]
>>> board[0][0] = "X"
>>> board
[['X', '', ''], ['', '', ''], ['', '', '']]
▶ Переменная Шредингера *
funcs = []
results = []
for x in range(7):
def some_func():
return x
funcs.append(some_func)
results.append(some_func()) # обратите внимание на вызов функции
funcs_results = [func() for func in funcs]
Вывод (Python version):
>>> results
[0, 1, 2, 3, 4, 5, 6]
>>> funcs_results
[6, 6, 6, 6, 6, 6, 6]
Значения x были разными в каждой итерации до добавления some_func к funcs, но все функции возвращают 6, когда они исполняются после завершения цикла.
>>> powers_of_x = [lambda x: x**i for i in range(10)]
>>> [f(2) for f in powers_of_x]
[512, 512, 512, 512, 512, 512, 512, 512, 512, 512]
💡 Объяснение:
- При определении функции внутри цикла, которая использует переменную цикла в своем теле, цикл функции привязывается к переменной, а не к ее значению. Функция ищет
xв окружающем контексте, а не использует значениеxна момент создания функции. Таким образом, все функции используют для вычислений последнее значение, присвоенное переменной. Мы можем видеть, что используетсяxиз глобального контекста (т.е. не локальная переменная):
>>> import inspect
>>> inspect.getclosurevars(funcs[0])
ClosureVars(nonlocals={}, globals={'x': 6}, builtins={}, unbound=set())
Так как x - глобальная переменная, можно изменить ее значение, которое будет использовано и возвращено из funcs
>>> x = 42
>>> [func() for func in funcs]
[42, 42, 42, 42, 42, 42, 42]
- Чтобы получить желаемое поведение, вы можете передать переменную цикла как именованную переменную в функцию. Почему это работает? Потому что это определит переменную внутри области видимости функции. Она больше не будет обращаться к глобальной области видимости для поиска значения переменной, а создаст локальную переменную, которая будет хранить значение
xв данный момент времени.
funcs = []
for x in range(7):
def some_func(x=x):
return x
funcs.append(some_func)
Вывод:
>>> funcs_results = [func() for func in funcs]
>>> funcs_results
[0, 1, 2, 3, 4, 5, 6]
x больше не используется в глобальной области видимости
>>> inspect.getclosurevars(funcs[0])
ClosureVars(nonlocals={}, globals={}, builtins={}, unbound=set())
▶ Проблема курицы и яйца *
1.
>>> isinstance(3, int)
True
>>> isinstance(type, object)
True
>>> isinstance(object, type)
True
Так какой же базовый класс является "окончательным"? Кстати, это еще не все,
2.
>>> class A: pass
>>> isinstance(A, A)
False
>>> isinstance(type, type)
True
>>> isinstance(object, object)
True
3.
>>> issubclass(int, object)
True
>>> issubclass(type, object)
True
>>> issubclass(object, type)
False
💡 Объяснение
type- это метакласс в Python.- Все в Python является
объектом, что включает в себя как классы, так и их объекты (экземпляры). - Класс
typeявляется метаклассом классаobject, и каждый класс (включаяtype) наследуется прямо или косвенно отobject. - У
objectиtypeнет реального базового класса. Путаница в приведенных выше фрагментах возникает потому, что мы думаем об этих отношениях (issubclassиisinstance) в терминах классов Python. Отношения междуobjectиtypeне могут быть воспроизведены в чистом Python. Точнее говоря, следующие отношения не могут быть воспроизведены в чистом Python,- класс A является экземпляром класса B, а класс B является экземпляром класса A.
- класс A является экземпляром самого себя.
- Эти отношения между
objectиtype(оба являются экземплярами друг друга, а также самих себя) существуют в Python из-за "обмана" на уровне реализации.
▶ Отношения между подклассами
Вывод:
>>> from collections import Hashable
>>> issubclass(list, object)
True
>>> issubclass(object, Hashable)
True
>>> issubclass(list, Hashable)
False
Предполагается, что отношения подклассов должны быть транзитивными, верно? (т.е. если A является подклассом B, а B является подклассом C, то A должен быть подклассом C)
💡 Объяснение
- Отношения подклассов не обязательно являются транзитивными в Python. Можно переопределить магический метод
__subclasscheck__в метаклассе. - Когда вызывается
issubclass(cls, Hashable), он просто ищет не-фальшивый метод "__hash__" вclsили во всем, от чего он наследуется. - Поскольку
objectявляется хэшируемым, аlist- нехэшируемым, это нарушает отношение транзитивности. - Более подробное объяснение можно найти [здесь] (https://www.naftaliharris.com/blog/python-subclass-intransitivity/).
▶ Равенство и тождество методов
class SomeClass:
def method(self):
pass
@classmethod
def classm(cls):
pass
@staticmethod
def staticm():
pass
Результат:
>>> print(SomeClass.method is SomeClass.method)
True
>>> print(SomeClass.classm is SomeClass.classm)
False
>>> print(SomeClass.classm == SomeClass.classm)
True
>>> print(SomeClass.staticm is SomeClass.staticm)
True
Обращаясь к classm дважды, мы получаем одинаковый объект, но не тот же самый? Давайте посмотрим, что происходит
с экземплярами SomeClass:
o1 = SomeClass()
o2 = SomeClass()
Вывод:
>>> print(o1.method == o2.method)
False
>>> print(o1.method == o1.method)
True
>>> print(o1.method is o1.method)
False
>>> print(o1.classm is o1.classm)
False
>>> print(o1.classm == o1.classm == o2.classm == SomeClass.classm)
True
>>> print(o1.staticm is o1.staticm is o2.staticm is SomeClass.staticm)
True
Повторный доступ к классу или методу создает одинаковые, но не те же самые объекты для одного и того же экземпляра какого-либо класса.
💡 Объяснение
- Функции являются дескрипторами. Всякий раз, когда к функции обращаются как к
атрибута, вызывается дескриптор, создавая объект метода, который "связывает" функцию с объектом, владеющим атрибутом. При вызове метод вызывает функцию, неявно передавая связанный объект в качестве первого аргумента
(именно так мы получаем
selfв качестве первого аргумента, несмотря на то, что не передаем его явно).
>>> o1.method
<bound method SomeClass.method of <__main__.SomeClass object at ...>>
- При многократном обращении к атрибуту каждый раз создается объект метода! Поэтому
o1.method is o1.methodвсегда ложно. Однако доступ к функциям как к атрибутам класса (в отличие от экземпляра) не создает методов; поэтомуSomeClass.method is SomeClass.methodявляется истинным.
>>> SomeClass.method
<function SomeClass.method at ...>
classmethodпреобразует функции в методы класса. Методы класса - это дескрипторы, которые при обращении к ним создают объект метода, который связывает класс (тип) объекта, а не сам объект.
>>> o1.classm
<bound method SomeClass.classm of <class '__main__.SomeClass'>>
- В отличие от функций,
classmethodбудет создавать метод и при обращении к нему как к атрибуту класса (в этом случае они привязываются к классу, а не к его типу). ПоэтомуSomeClass.classm is SomeClass.classmявляется ошибочным.
>>> SomeClass.classm
<bound method SomeClass.classm of <class '__main__.SomeClass'>>
- Объект-метод равен, если обе функции равны, а связанные объекты одинаковы. Поэтому
o1.method == o1.methodявляется истинным, хотя и не является одним и тем же объектом в памяти. staticmethodпреобразует функции в дескриптор "no-op", который возвращает функцию как есть. Методы-объекты никогда не создается, поэтому сравнение сisявляется истинным.
>>> o1.staticm
<function SomeClass.staticm at ...>
>>> SomeClass.staticm
<function SomeClass.staticm at ...>
- Необходимость создавать новые объекты "метод" каждый раз, когда Python вызывает методы экземпляра, и необходимость изменять аргументы
каждый раз, чтобы вставить
self, сильно сказывается на производительности. CPython 3.7 решил эту проблему, введя новые опкоды, которые работают с вызовом методов без создания временных объектов методов. Это используется только при фактическом вызове функции доступа, так что приведенные здесь фрагменты не затронуты и по-прежнему генерируют методы :)
▶ All-true-ation (непереводимая игра слов) *
>>> all([True, True, True])
True
>>> all([True, True, False])
False
>>> all([])
True
>>> all([[]])
False
>>> all([[[]]])
True
Почему это изменение True-False?
💡 Объяснение:
-
Реализация функции
all: -
def all(iterable): for element in iterable: if not element: return False return True -
all([])возвращаетTrue, поскольку итерируемый массив пуст. -
all([[]])возвращаетFalse, поскольку переданный массив имеет один элемент,[], а в python пустой список является ложным. -
all([[[[]]])и более высокие рекурсивные варианты всегдаTrue. Это происходит потому, что единственный элемент переданного массива ([[...]]) уже не пуст, а списки со значениями являются истинными.
▶ Неожиданная запятая
Вывод (< 3.6):
>>> def f(x, y,):
... print(x, y)
...
>>> def g(x=4, y=5,):
... print(x, y)
...
>>> def h(x, **kwargs,):
File "<stdin>", line 1
def h(x, **kwargs,):
^
SyntaxError: invalid syntax
>>> def h(*args,):
File "<stdin>", line 1
def h(*args,):
^
SyntaxError: invalid syntax
💡 Объяснение:
- Запятая в конце списка аргументов функции Python не всегда законна.
- В Python список аргументов определяется частично с помощью ведущих запятых, а частично с помощью запятых в конце списка. Этот конфликт приводит к ситуациям, когда запятая оказывается в середине, и ни одно из правил не выполняется.
- Примечание: Проблема с запятыми в конце списка аргументов исправлена в Python 3.6. Варианты использования запятых в конце выражения приведены в обсуждении.
▶ Строки и обратные слэши
Вывод:
>>> print("\"")
"
>>> print(r"\"")
\"
>>> print(r"\")
File "<stdin>", line 1
print(r"\")
^
SyntaxError: EOL while scanning string literal
>>> r'\'' == "\\'"
True
💡 Объяснение
- В обычной строке обратная слэш используется для экранирования символов, которые могут иметь специальное значение (например, одинарная кавычка, двойная кавычка и сам обратный слэш).
>>> "wt\"f" 'wt"f' - В необработанном строковом литерале (на что указывает префикс
r) обратный слэш передается как есть, вместе с поведением экранирования следующего символа.>>> r'wt\"f' == 'wt\\"f' True >>> print(repr(r'wt\"f') 'wt\\"f' >>> print("\n") >>> print(r"\\n") '\\n' - Это означает, что когда синтаксический анализатор встречает обратный слэш в необработанной строке, он ожидает, что за ней последует другой символ. А в нашем случае (
print(r"\")) обратная слэш экранирует двойную кавычку, оставив парсер без завершающей кавычки (отсюдаSyntaxError). Вот почему обратный слеш не работает в конце необработанной строки.
--
▶ Не узел! (eng. not knot!)
x = True
y = False
Результат:
>>> not x == y
True
>>> x == not y
File "<input>", line 1
x == not y
^
SyntaxError: invalid syntax
💡 Объяснение
- Старшинство операторов влияет на выполнение выражения, и оператор
==имеет более высокий приоритет, чем операторnotв Python. - Поэтому
not x == yэквивалентноnot (x == y), что эквивалентноnot (True == False), в итоге равноеTrue. - Но
x == not yвызываетSyntaxError, потому что его можно считать эквивалентным(x == not) y, а неx == (not y), что можно было бы ожидать на первый взгляд. - Парсер ожидал, что ключевое слово
notбудет частью оператораnot in(потому что оба оператора==иnot inимеют одинаковый приоритет), но после того, как он не смог найти ключевое словоin, следующее заnot, он выдаетSyntaxError.
▶ Строки наполовину в тройных кавычках
Вывод:
>>> print('wtfpython''')
wtfpython
>>> print("wtfpython""")
wtfpython
>>> # Выражения ниже приводят к `SyntaxError`
>>> # print('''wtfpython')
>>> # print("""wtfpython")
File "<input>", line 3
print("""wtfpython")
^
SyntaxError: EOF while scanning triple-quoted string literal
💡 Объяснение:
- Python поддерживает неявную конкатенацию строковых литералов, Пример,
>>> print("wtf" "python") wtfpython >>> print("wtf" "") # or "wtf""" wtf '''и"""также являются разделителями строк в Python, что вызывает SyntaxError, поскольку интерпретатор Python ожидал завершающую тройную кавычку в качестве разделителя при сканировании текущего встреченного строкового литерала с тройной кавычкой.
▶ Что не так с логическими значениями?
1.
# Простой пример счетчика логических переменных и целых чисел
# в итерируемом объекте со значениями разных типов данных
mixed_list = [False, 1.0, "some_string", 3, True, [], False]
integers_found_so_far = 0
booleans_found_so_far = 0
for item in mixed_list:
if isinstance(item, int):
integers_found_so_far += 1
elif isinstance(item, bool):
booleans_found_so_far += 1
Результат:
>>> integers_found_so_far
4
>>> booleans_found_so_far
0
2.
>>> some_bool = True
>>> "wtf" * some_bool
'wtf'
>>> some_bool = False
>>> "wtf" * some_bool
''
3.
def tell_truth():
True = False
if True == False:
print("I have lost faith in truth!")
Результат (< 3.x):
>>> tell_truth()
I have lost faith in truth!
💡 Объяснение:
-
boolэто подкласс классаintв Python>>> issubclass(bool, int) True >>> issubclass(int, bool) False -
TrueиFalse- экземпляры классаint>>> isinstance(True, int) True >>> isinstance(False, int) True -
Целочисленное значение
Trueравно1, аFalseравно0.>>> int(True) 1 >>> int(False) 0 -
Объяснение на StackOverflow.
-
Изначально в Python не было типа
bool(использовали 0 для false и ненулевое значение 1 для true). В версиях 2.x были добавленыTrue,Falseи типbool, но для обратной совместимостиTrueиFalseнельзя было сделать константами. Они просто были встроенными переменными, и их можно было переназначить. -
Python 3 был несовместим с предыдущими версиями, эту проблему наконец-то исправили, и поэтому последний фрагмент не будет работать с Python 3.x!
▶ Атрибуты класса и экземпляра
1.
class A:
x = 1
class B(A):
pass
class C(A):
pass
Результат:
>>> A.x, B.x, C.x
(1, 1, 1)
>>> B.x = 2
>>> A.x, B.x, C.x
(1, 2, 1)
>>> A.x = 3
>>> A.x, B.x, C.x # Значение C.x изменилось , но B.x - нет
(3, 2, 3)
>>> a = A()
>>> a.x, A.x
(3, 3)
>>> a.x += 1
>>> a.x, A.x
(4, 3)
2.
class SomeClass:
some_var = 15
some_list = [5]
another_list = [5]
def __init__(self, x):
self.some_var = x + 1
self.some_list = self.some_list + [x]
self.another_list += [x]
Результат:
>>> some_obj = SomeClass(420)
>>> some_obj.some_list
[5, 420]
>>> some_obj.another_list
[5, 420]
>>> another_obj = SomeClass(111)
>>> another_obj.some_list
[5, 111]
>>> another_obj.another_list
[5, 420, 111]
>>> another_obj.another_list is SomeClass.another_list
True
>>> another_obj.another_list is some_obj.another_list
True
💡 Объяснение:
- Переменные класса и переменные экземпляров класса внутренне обрабатываются как словари объекта класса. Если имя переменной не найдено в словаре текущего класса, оно ищется в родительских классах.
- Оператор += изменяет объект на месте, не создавая новый объект. Таким образом, изменение атрибута одного экземпляра влияет на другие экземпляры и атрибут класса также.
▶ Возврат None из генератора
some_iterable = ('a', 'b')
def some_func(val):
return "something"
Результат (<= 3.7.x):
>>> [x for x in some_iterable]
['a', 'b']
>>> [(yield x) for x in some_iterable]
<generator object <listcomp> at 0x7f70b0a4ad58>
>>> list([(yield x) for x in some_iterable])
['a', 'b']
>>> list((yield x) for x in some_iterable)
['a', None, 'b', None]
>>> list(some_func((yield x)) for x in some_iterable)
['a', 'something', 'b', 'something']
💡 Объяснение:
- Это баг в обработке yield в генераторах и списочных выражениях CPython.
- Исходный код и объяснение можно найти здесь
- Связанный отчет об ошибке
- В Python 3.8+ yield внутри списочных выражений больше не допускается и выдает
SyntaxError.
▶ Yield from возвращает... *
1.
def some_func(x):
if x == 3:
return ["wtf"]
else:
yield from range(x)
Результат (> 3.3):
>>> list(some_func(3))
[]
Куда исчезло "wtf"? Это связано с каким-то особым эффектом yield from? Проверим это.
2.
def some_func(x):
if x == 3:
return ["wtf"]
else:
for i in range(x):
yield i
Результат:
>>> list(some_func(3))
[]
То же самое, это тоже не сработало. Что происходит?
💡 Объяснение:
- С Python 3.3 стало возможным использовать оператор
returnв генераторах с возвращением значения (см. PEP380). В официальной документации говорится, что
"...
return exprв генераторе вызывает исключениеStopIteration(expr)при выходе из генератора."
-
В случае
some_func(3)StopIterationвозникает в начале из-за оператораreturn. ИсключениеStopIterationавтоматически перехватывается внутри оберткиlist(...)и циклаfor. Поэтому два вышеприведенных фрагмента приводят к пустому списку. -
Чтобы получить
["wtf"]из генератораsome_func, нужно перехватить исключениеStopIteration.try: next(some_func(3)) except StopIteration as e: some_string = e.value>>> some_string ["wtf"]
▶ Nan-рефлексивность *
1.
a = float('inf')
b = float('nan')
c = float('-iNf') # Эти строки не чувствительны к регистру
d = float('nan')
Результат:
>>> a
inf
>>> b
nan
>>> c
-inf
>>> float('some_other_string')
ValueError: could not convert string to float: some_other_string
>>> a == -c # inf==inf
True
>>> None == None # None == None
True
>>> b == d # но nan!=nan
False
>>> 50 / a
0.0
>>> a / a
nan
>>> 23 + b
nan
2.
>>> x = float('nan')
>>> y = x / x
>>> y is y # идендичность сохраняется
True
>>> y == y # сравнение ложно для y
False
>>> [y] == [y] # но сравнение истинно для списка, содержащего y
True
💡 Объяснение:
-
'inf'и'nan'- это специальные строки (без учета регистра), которые при явном приведении к типуfloatиспользуются для представления математической "бесконечности" и "не число" соответственно. -
Согласно стандартам IEEE
NaN != NaN, но соблюдение этого правила нарушает предположение о рефлексивности элемента коллекции в Python, то есть еслиxявляется частью коллекции, такой какlist, реализации, методы сравнения предполагают, чтоx == x. Поэтому при сравнении элементов сначала сравниваются их идентификаторы (так как это быстрее), а значения сравниваются только при несовпадении идентификаторов. Следующий фрагмент сделает вещи более ясными:>>> x = float('nan') >>> x == x, [x] == [x] (False, True) >>> y = float('nan') >>> y == y, [y] == [y] (False, True) >>> x == y, [x] == [y] (False, False)Поскольку идентификаторы
xиyразные, рассматриваются значения, которые также различаются; следовательно, на этот раз сравнение возвращаетFalse. -
Интересное чтение: Рефлексивность и другие основы цивилизации
▶ Мутируем немутируемое!
Это может показаться тривиальным, если вы знаете, как работают ссылки в Python.
some_tuple = ("A", "tuple", "with", "values")
another_tuple = ([1, 2], [3, 4], [5, 6])
Результат:
>>> some_tuple[2] = "change this"
TypeError: 'tuple' object does not support item assignment
>>> another_tuple[2].append(1000) # Не приводит к исключениям
>>> another_tuple
([1, 2], [3, 4], [5, 6, 1000])
>>> another_tuple[2] += [99, 999]
TypeError: 'tuple' object does not support item assignment
>>> another_tuple
([1, 2], [3, 4], [5, 6, 1000, 99, 999])
Но кортежи неизменяемы... Что происходит?
💡 Объяснение:
-
Перевод цитаты из документации
Неизменяемые последовательности Объект неизменяемого типа последовательности не может измениться после создания. (Если объект содержит ссылки на другие объекты, эти объекты могут быть изменяемыми и могут быть изменены; однако набор объектов, на которые непосредственно ссылается неизменяемый объект, не может изменяться.)
-
Оператор
+=изменяет список на месте. Присваивание элемента не работает, но когда возникает исключение, элемент уже был изменен на месте. -
Также есть объяснение в официальном Python FAQ.
▶ Исчезающая переменная из внешней области видимости
e = 7
try:
raise Exception()
except Exception as e:
pass
Результат (Python 2.x):
>>> print(e)
# Ничего не выводит
Результат (Python 3.x):
>>> print(e)
NameError: name 'e' is not defined
💡 Объяснение:
Когда исключение было назначено с помощью ключевого слова as, оно очищается в конце блока except. Это происходит так, как если бы
except E as N:
foo
разворачивалось до
except E as N:
try:
foo
finally:
del N
Это означает, что исключению должно быть присвоено другое имя, чтобы на него можно было ссылаться после завершения блока except. Исключения очищаются, потому что с прикрепленным к ним трейсбэком они образуют цикл ссылок со стеком вызовов, сохраняя все локальные объекты в этой стэке до следующей сборки мусора.
- В Python clauses не имеют области видимости. В примере все объекты в одной области видимости, а переменная
eбыла удалена из-за выполнения блокаexcept. Этого нельзя сказать о функциях, которые имеют отдельные внутренние области видимости. Пример ниже иллюстрирует это:
def f(x):
del(x)
print(x)
x = 5
y = [5, 4, 3]
```
**Результат:**
```py
>>> f(x)
UnboundLocalError: local variable 'x' referenced before assignment
>>> f(y)
UnboundLocalError: local variable 'x' referenced before assignment
>>> x
5
>>> y
[5, 4, 3]
```
* В Python 2.x, имя переменной `e` назначается на экземпляр `Exception()`, и при попытки вывести значение `e` ничего не выводится.
**Результат (Python 2.x):**
```py
>>> e
Exception()
>>> print e
# Ничего не выводится!
```
---
### ▶ Загадочное преобразование типов ключей
<!-- Example ID: 00f42dd0-b9ef-408d-9e39-1bc209ce3f36 --->
```py
class SomeClass(str):
pass
some_dict = {'s': 42}
Результат:
>>> type(list(some_dict.keys())[0])
str
>>> s = SomeClass('s')
>>> some_dict[s] = 40
>>> some_dict # Ожидается 2 разные пары ключ-значение
{'s': 40}
>>> type(list(some_dict.keys())[0])
str
💡 Объяснение:
-
И объект
s, и строка"s"хэшируются до одного и того же значения, потому чтоSomeClassнаследует метод__hash__классаstr. -
Выражение
SomeClass("s") == "s"эквивалентноTrue, потому чтоSomeClassтакже наследует метод__eq__классаstr. -
Поскольку оба объекта хэшируются на одно и то же значение и равны, они представлены одним и тем же ключом в словаре.
-
Чтобы добиться желаемого поведения, мы можем переопределить метод
__eq__вSomeClass.class SomeClass(str): def __eq__(self, other): return ( type(self) is SomeClass and type(other) is SomeClass and super().__eq__(other) ) # При переопределении метода __eq__, Python прекращает автоматическое наследование метода # __hash__, поэтому его нужно вручную определить __hash__ = str.__hash__ some_dict = {'s':42}Результат:
>>> s = SomeClass('s') >>> some_dict[s] = 40 >>> some_dict {'s': 40, 's': 42} >>> keys = list(some_dict.keys()) >>> type(keys[0]), type(keys[1]) (__main__.SomeClass, str)
▶ Посмотрим, сможете ли вы угадать что здесь?
a, b = a[b] = {}, 5
Результат:
>>> a
{5: ({...}, 5)}
💡 Объяснение:
- Согласно документации, выражения присваивания имеют вид
и(target_list "=")+ (expression_list | yield_expression)
Оператор присваивания исполняет список выражений (помните, что это может быть одно выражение или список, разделенный запятыми, в последнем случае получается кортеж) и присваивает единственный результирующий объект каждому из целевых списков, слева направо.
-
+в(target_list "=")+означает, что может быть один или более целевых списков. В данном случае целевыми списками являютсяa, bиa[b](обратите внимание, что список выражений ровно один, в нашем случае это{}, 5). -
После исполнения списка выражений его значение распаковывается в целевые списки слева направо. Так, в нашем случае сначала кортеж
{}, 5распаковывается вa, b, и теперь у нас естьa = {}иb = 5. -
Теперь
aимеет значение{}, которое является изменяемым объектом. -
Вторым целевым списком является
a[b](вы можете ожидать, что это вызовет ошибку, посколькуaиbне были определены в предыдущих утверждениях. Но помните, мы только что присвоилиaзначение{}иb-5). -
Теперь мы устанавливаем ключ
5в словаре в кортеж({}, 5), создавая круговую ссылку ({...}в выводе ссылается на тот же объект, на который уже ссылаетсяa). Другим более простым примером круговой ссылки может быть
>>> some_list
[[...]]
>>> some_list[0]
[[...]]
>>> some_list is some_list[0]
True
>>> some_list[0][0][0][0][0][0] == some_list
True
Аналогичный случай в примере выше (a[b][0] - это тот же объект, что и a)
-
Подводя итог, можно разбить пример на следующие пункты
a, b = {}, 5 a[b] = a, bА циклическая ссылка может быть оправдана тем, что
a[b][0]- тот же объект, что иa>>> a[b][0] is a True
▶ Превышение предела целочисленного преобразования строк
>>> # Python 3.10.6
>>> int("2" * 5432)
>>> # Python 3.10.8
>>> int("2" * 5432)
Вывод:
>>> # Python 3.10.6
222222222222222222222222222222222222222222222222222222222222222...
>>> # Python 3.10.8
Traceback (most recent call last):
...
ValueError: Exceeds the limit (4300) for integer string conversion:
value has 5432 digits; use sys.set_int_max_str_digits()
to increase the limit.
💡 Объяснение:
Этот вызов int() прекрасно работает в Python 3.10.6 и вызывает ошибку ValueError в Python 3.10.8, 3.11. Обратите внимание, что Python все еще может работать с большими целыми числами. Ошибка возникает только при преобразовании между целыми числами и строками.
К счастью, вы можете увеличить предел допустимого количества цифр. Для этого можно воспользоваться одним из следующих способов:
-X int_max_str_digits- флаг командной строкиcommand-line flagset_int_max_str_digits()- функция из модуляsysPYTHONINTMAXSTRDIGITS- переменная окружения
Смотри документацию для получения более подробной информации об изменении лимита по умолчанию, если вы ожидаете, что ваш код превысит это значение.
Секция: Скользкие склоны
▶ Изменение словаря во время прохода по нему
x = {0: None}
for i in x:
del x[i]
x[i+1] = None
print(i)
Результат (Python 2.7- Python 3.5):
0
1
2
3
4
5
6
7
Да, цикл выполняет ровно восемь итераций и завершается.
💡 Объяснение:
- Проход по словарю и его одновременное редактирование не поддерживается.
- Выполняется восемь проходов, потому что именно в этот момент словарь изменяет размер, чтобы вместить больше ключей (у нас есть восемь записей об удалении, поэтому необходимо изменить размер). На самом деле это деталь реализации.
- То, как обрабатываются удаленные ключи и когда происходит изменение размера, может отличаться в разных реализациях Python.
- Так что для версий Python, отличных от Python 2.7 - Python 3.5, количество записей может отличаться от 8 (но каким бы ни было количество записей, оно будет одинаковым при каждом запуске). Обсуждения по этому поводу имеются в issue и на StackOverflow.
- В Python 3.7.6 и выше при попытке запустить пример вызывается исключение
RuntimeError: dictionary keys changed during iteration.
▶ Упрямая операция del
class SomeClass:
def __del__(self):
print("Deleted!")
Результат: 1.
>>> x = SomeClass()
>>> y = x
>>> del x # должно быть выведено "Deleted!"
>>> del y
Deleted!
Фух, наконец-то удалили. Вы, наверное, догадались, что спасло __del__ от вызова в нашей первой попытке удалить x. Давайте добавим в пример еще больше изюминок.
2.
>>> x = SomeClass()
>>> y = x
>>> del x
>>> y # проверяем, существует ли y
<__main__.SomeClass instance at 0x7f98a1a67fc8>
>>> del y # Как и в прошлом примере, вывод должен содержать "Deleted!"
>>> globals() # но вывод пуст. Проверим все глобальные переменные
Deleted!
{'__builtins__': <module '__builtin__' (built-in)>, 'SomeClass': <class __main__.SomeClass at 0x7f98a1a5f668>, '__package__': None, '__name__': '__main__', '__doc__': None}
Вот сейчас переменная y удалена 😕
💡 Объяснение:
del xне вызывает напрямуюx.__del__().- Когда встречается
del x, Python удаляет имяxиз текущей области видимости и уменьшает на 1 количество ссылок на объект, на который ссылаетсяx.__del__()вызывается только тогда, когда счетчик ссылок объекта достигает нуля. - Во втором фрагменте вывода
__del__()не была вызвана, потому что предыдущий оператор (>>> y) в интерактивном интерпретаторе создал еще одну ссылку на тот же объект (в частности, магическую переменную_, которая ссылается на значение результата последнего неNoneвыражения в REPL), тем самым не позволив счетчику ссылок достичь нуля, когда было встреченоdel y. - Вызов
globals(или вообще выполнение чего-либо, что будет иметь результат, отличный отNone) заставил_сослаться на новый результат, отбросив существующую ссылку. Теперь количество ссылок достигло 0, и мы можем видеть, как выводится "Deleted!" (наконец-то!).
▶ Переменная за пределами видимости
1.
a = 1
def some_func():
return a
def another_func():
a += 1
return a
2.
def some_closure_func():
a = 1
def some_inner_func():
return a
return some_inner_func()
def another_closure_func():
a = 1
def another_inner_func():
a += 1
return a
return another_inner_func()
Результат:
>>> some_func()
1
>>> another_func()
UnboundLocalError: local variable 'a' referenced before assignment
>>> some_closure_func()
1
>>> another_closure_func()
UnboundLocalError: local variable 'a' referenced before assignment
💡 Объяснение:
-
Когда вы делаете присваивание переменной в области видимости, она становится локальной для этой области. Так
aстановится локальной для области видимостиanother_func, но она не была инициализирована ранее в той же области видимости, что приводит к ошибке. -
Для изменения переменной
aиз внешней области видимости внутри функцииanother_func, необходимо использовать ключевое словоglobal.def another_func() global a a += 1 return aРезультат:
>>> another_func() 2 -
В
another_closure_funcпеременнаяaстановится локальной для области видимостиanother_inner_func, но она не была инициализирована ранее в той же области видимости, поэтому выдает ошибку. -
Чтобы изменить переменную внешней области видимости
aвanother_inner_func, используйте ключевое словоnonlocal. Утверждение nonlocal используется для обращения к переменным, определенным в ближайшей внешней (за исключением глобальной) области видимости.def another_func(): a = 1 def another_inner_func(): nonlocal a a += 1 return a return another_inner_func()Результат:
>>> another_func() 2 -
Ключевые слова
globalиnonlocalуказывают интерпретатору python не объявлять новые переменные и искать их в соответствующих внешних областях видимости. -
Прочитайте это короткое, но потрясающее руководство, чтобы узнать больше о том, как работают пространства имен и разрешение областей видимости в Python.
▶ Удаление элемента списка во время прохода по списку
list_1 = [1, 2, 3, 4]
list_2 = [1, 2, 3, 4]
list_3 = [1, 2, 3, 4]
list_4 = [1, 2, 3, 4]
for idx, item in enumerate(list_1):
del item
for idx, item in enumerate(list_2):
list_2.remove(item)
for idx, item in enumerate(list_3[:]):
list_3.remove(item)
for idx, item in enumerate(list_4):
list_4.pop(idx)
Результат:
>>> list_1
[1, 2, 3, 4]
>>> list_2
[2, 4]
>>> list_3
[]
>>> list_4
[2, 4]
Есть предположения, почему вывод [2, 4]?
💡 Объяснение:
- Никогда не стоит изменять объект, над которым выполняется итерация. Правильным способом будет итерация по копии объекта, и
list_3[:]делает именно это.>>> some_list = [1, 2, 3, 4] >>> id(some_list) 139798789457608 >>> id(some_list[:]) # Notice that python creates new object for sliced list. 139798779601192
Разница между del, remove и pop:
del var_nameпросто удаляет привязкуvar_nameиз локального или глобального пространства имен (поэтомуlist_1не затрагивается).removeудаляет первое подходящее значение, а не конкретный индекс, вызываетValueError, если значение не найдено.popудаляет элемент по определенному индексу и возвращает его, вызываетIndexError, если указан неверный индекс.
**Почему на выходе получается [2, 4]?
- Проход по списку выполняется индекс за индексом, и когда мы удаляем
1изlist_2илиlist_4, содержимое списков становится[2, 3, 4]. Оставшиеся элементы сдвинуты вниз, то есть2находится на индексе 0, а3- на индексе 1. Поскольку на следующей итерации будет просматриваться индекс 1 (который и есть3),2будет пропущен полностью. Аналогичное произойдет с каждым альтернативным элементом в последовательности списка.
- Объяснение примера можно найти на StackOverflow.
- Также посмотрите на похожий пример на StackOverflow, связанный со словарями.
▶ Сжатие итераторов с потерями *
>>> numbers = list(range(7))
>>> numbers
[0, 1, 2, 3, 4, 5, 6]
>>> first_three, remaining = numbers[:3], numbers[3:]
>>> first_three, remaining
([0, 1, 2], [3, 4, 5, 6])
>>> numbers_iter = iter(numbers)
>>> list(zip(numbers_iter, first_three))
[(0, 0), (1, 1), (2, 2)]
# пока все хорошо, сожмем оставшуюся часть итератора
>>> list(zip(numbers_iter, remaining))
[(4, 3), (5, 4), (6, 5)]
Куда пропал элемент 3 из списка numbers?
💡 Объяснение:
- Согласно документации, примерная реализация функции
zipвыглядит так,def zip(*iterables): sentinel = object() iterators = [iter(it) for it in iterables] while iterators: result = [] for it in iterators: elem = next(it, sentinel) if elem is sentinel: return result.append(elem) yield tuple(result) - Таким образом, функция принимает произвольное количество итерируемых объектов, добавляет каждый из их элементов в список
result, вызывая для них функциюnext, и останавливается всякий раз, когда любой из итерируемых объектов исчерпывается. - Нюанс заключается в том, что при исчерпании любого итерируемого объекта существующие элементы в списке
resultотбрасываются. Именно это произошло с3вnumbers_iter. - Правильный способ выполнения вышеописанных действий с помощью
zipбудет следующим,
Первый аргумент сжатия должен иметь наименьшее число элементов>>> numbers = list(range(7)) >>> numbers_iter = iter(numbers) >>> list(zip(first_three, numbers_iter)) [(0, 0), (1, 1), (2, 2)] >>> list(zip(remaining, numbers_iter)) [(3, 3), (4, 4), (5, 5), (6, 6)]
▶ Утечка переменных внутри цикла
1.
for x in range(7):
if x == 6:
print(x, ': for x inside loop')
print(x, ': x in global')
Вывод:
6 : for x inside loop
6 : x in global
Но x не была определена за пределами цикла for...
2.
# В этот раз определим x до цикла
x = -1
for x in range(7):
if x == 6:
print(x, ': for x inside loop')
print(x, ': x in global')
Вывод:
6 : for x inside loop
6 : x in global
3.
Вывод (Python 2.x):
>>> x = 1
>>> print([x for x in range(5)])
[0, 1, 2, 3, 4]
>>> print(x)
4
Вывод (Python 3.x):
>>> x = 1
>>> print([x for x in range(5)])
[0, 1, 2, 3, 4]
>>> print(x)
1
💡 Объяснение:
-
В Python циклы for используют область видимости, в которой они существуют, и оставляют свою определенную переменную цикла после завершения. Это также относится к случаям, когда мы явно определили переменную цикла for в глобальном пространстве имен. В этом случае будет произведена перепривязка существующей переменной.
-
Различия в выводе интерпретаторов Python 2.x и Python 3.x для примера с пониманием списков можно объяснить следующим изменением, задокументированным в журнале изменений What's New In Python 3.0:
"Генераторы списков ("list comprehensions") больше не поддерживает синтаксическую форму
[... for var in item1, item2, ...]. Вместо этого используйте[... for var in (item1, item2, ...)]. Кроме того, обратите внимание, что генераторы списков имеют другую семантику: они ближе к синтаксическому сахару для генераторного выражения внутри конструктораlist(), и, в частности, управляющие переменные цикла больше не просачиваются в окружающую область видимости."
▶ Остерегайтесь изменяемых аргументов по умолчанию!
def some_func(default_arg=[]):
default_arg.append("some_string")
return default_arg
Результат:
>>> some_func()
['some_string']
>>> some_func()
['some_string', 'some_string']
>>> some_func([])
['some_string']
>>> some_func()
['some_string', 'some_string', 'some_string']
💡 Объяснение:
-
Изменяемые аргументы функций по умолчанию в Python на самом деле не инициализируются каждый раз, когда вы вызываете функцию. Вместо этого в качестве значения по умолчанию используется недавно присвоенное им значение. Когда мы явно передали
[]вsome_func в качестве аргумента, значение по умолчанию переменнойdefault_arg` не было использовано, поэтому функция вернулась, как и ожидалось.def some_func(default_arg=[]): default_arg.append("some_string") return default_argРезультат:
>>> some_func.__defaults__ # Выражение выведет значения стандартных аргументов фукнции ([],) >>> some_func() >>> some_func.__defaults__ (['some_string'],) >>> some_func() >>> some_func.__defaults__ (['some_string', 'some_string'],) >>> some_func([]) >>> some_func.__defaults__ (['some_string', 'some_string'],) -
Чтобы избежать ошибок, связанных с изменяемыми аргументами, принято использовать
Noneв качестве значения по умолчанию, а затем проверять, передано ли какое-либо значение в функцию, соответствующую этому аргументу. Пример:def some_func(default_arg=None): if default_arg is None: default_arg = [] default_arg.append("some_string") return default_arg
▶ Ловля исключений
some_list = [1, 2, 3]
try:
# Должно вернуться ``IndexError``
print(some_list[4])
except IndexError, ValueError:
print("Caught!")
try:
# Должно вернуться ``ValueError``
some_list.remove(4)
except IndexError, ValueError:
print("Caught again!")
Результат (Python 2.x):
Caught!
ValueError: list.remove(x): x not in list
Результат (Python 3.x):
File "<input>", line 3
except IndexError, ValueError:
^
SyntaxError: invalid syntax
💡 Объяснение
-
Чтобы добавить несколько Исключений в блок
except, необходимо передать их в виде кортежа с круглыми скобками в качестве первого аргумента. Второй аргумент - это необязательное имя, которое при передаче свяжет экземпляр исключения, который был пойман. Пример,some_list = [1, 2, 3] try: # Должно возникнуть ``ValueError`` some_list.remove(4) except (IndexError, ValueError), e: print("Caught again!") print(e)Результат (Python 2.x):
Caught again! list.remove(x): x not in listРезультат (Python 3.x):
File "<input>", line 4 except (IndexError, ValueError), e: ^ IndentationError: unindent does not match any outer indentation level -
Отделение исключения от переменной запятой является устаревшим и не работает в Python 3; правильнее использовать
as. Пример,some_list = [1, 2, 3] try: some_list.remove(4) except (IndexError, ValueError) as e: print("Caught again!") print(e)Результат:
Caught again! list.remove(x): x not in list
▶ Одни и те же операнды, разная история!
1.
a = [1, 2, 3, 4]
b = a
a = a + [5, 6, 7, 8]
Результат:
>>> a
[1, 2, 3, 4, 5, 6, 7, 8]
>>> b
[1, 2, 3, 4]
2.
a = [1, 2, 3, 4]
b = a
a += [5, 6, 7, 8]
Результат:
>>> a
[1, 2, 3, 4, 5, 6, 7, 8]
>>> b
[1, 2, 3, 4, 5, 6, 7, 8]
💡 Объяснение:
-
Выражение
a += bне всегда ведет себя так же, как иa = a + b. Классы могут по-разному реализовывать операторыop=, а списки ведут себя так. -
Выражение
a = a + [5,6,7,8]создает новый список и устанавливает ссылкуaна этот новый список, оставляяbнеизменным. -
Выражение
a += [5,6,7,8]фактически отображается на функцию "extend", которая работает со списком так, чтоaиbпо-прежнему указывают на тот же самый список, который был изменен на месте.
▶ Разрешение имен игнорирует область видимости класса
1.
x = 5
class SomeClass:
x = 17
y = (x for i in range(10))
Результат:
>>> list(SomeClass.y)[0]
5
2.
x = 5
class SomeClass:
x = 17
y = [x for i in range(10)]
Результат (Python 2.x):
>>> SomeClass.y[0]
17
Результат (Python 3.x):
>>> SomeClass.y[0]
5
💡 Объяснение
- Области видимости, вложенные внутрь определения класса, игнорируют имена, связанные на уровне класса.
- Выражение-генератор имеет свою собственную область видимости.
- Начиная с версии Python 3.X, списковые вычисления также имеют свою собственную область видимости.
▶ Округляясь как банкир *
Реализуем простейшую функцию по получению среднего элемента списка:
def get_middle(some_list):
mid_index = round(len(some_list) / 2)
return some_list[mid_index - 1]
Python 3.x:
>>> get_middle([1]) # вроде неплохо
1
>>> get_middle([1,2,3]) # все еще хорошо
2
>>> get_middle([1,2,3,4,5]) # что-то не то?
2
>>> len([1,2,3,4,5]) / 2 # хорошо
2.5
>>> round(len([1,2,3,4,5]) / 2) # почему снова так?
2
Кажется, Python округлил 2.5 до 2.
💡 Объяснение:
- Это не ошибка округления float, на самом деле такое поведение намеренно. Начиная с Python 3.0,
round()использует округление банкира, где дроби .5 округляются до ближайшего четного числа.
>>> round(0.5)
0
>>> round(1.5)
2
>>> round(2.5)
2
>>> import numpy # поведение numpy аналогично
>>> numpy.round(0.5)
0.0
>>> numpy.round(1.5)
2.0
>>> numpy.round(2.5)
2.0
-
Это рекомендуемый способ округления дробей до .5, описанный в IEEE 754. Однако в школах чаще всего преподают другой способ (округление от нуля), поэтому округление банкира, скорее всего, не так хорошо известно. Более того, некоторые из самых популярных языков программирования (например, JavaScript, Java, C/C++, Ruby, Rust) также не используют округление банкира. Таким образом, для Python это все еще довольно специфично и может привести к путанице при округлении дробей.
-
Дополнительную информацию можно найти в документации функции
roundили на StackOverflow.
▶ Иголки в стоге сена *
Я не встречал ни одного питониста на данный момент, который не встречался с одним из следующих сценариев,
1.
x, y = (0, 1) if True else None, None
Результат:
>>> x, y # ожидается (0, 1)
((0, 1), None)
2.
t = ('one', 'two')
for i in t:
print(i)
t = ('one')
for i in t:
print(i)
t = ()
print(t)
Результат:
one
two
o
n
e
tuple()
3.
ten_words_list = [
"some",
"very",
"big",
"list",
"that"
"consists",
"of",
"exactly",
"ten",
"words"
]
Результат
>>> len(ten_words_list)
9
4. Недостаточно твердое утверждение
a = "python"
b = "javascript"
Результат:
# assert выражение с сообщением об ошиб
>>> assert(a == b, "Both languages are different")
# Исключение AssertionError не возникло
5.
some_list = [1, 2, 3]
some_dict = {
"key_1": 1,
"key_2": 2,
"key_3": 3
}
some_list = some_list.append(4)
some_dict = some_dict.update({"key_4": 4})
Результат:
>>> print(some_list)
None
>>> print(some_dict)
None
6.
def some_recursive_func(a):
if a[0] == 0:
return
a[0] -= 1
some_recursive_func(a)
return a
def similar_recursive_func(a):
if a == 0:
return a
a -= 1
similar_recursive_func(a)
return a
Результат:
>>> some_recursive_func([5, 0])
[0, 0]
>>> similar_recursive_func(5)
4
💡 Объяснение:
-
Для 1 примера правильным выражением для ожидаемого поведения является
x, y = (0, 1) if True else (None, None). -
Для 2 примера правильным выражением для ожидаемого поведения будет
t = ('one',)илиt = 'one',(пропущена запятая), иначе интерпретатор рассматриваетtкакstrи перебирает его символ за символом. -
()- специальное выражение, обозначающая пустойtuple. -
В 3 примере, как вы, возможно, уже поняли, пропущена запятая после 5-го элемента (
"that") в списке. Таким образом, неявная конкатенация строковых литералов,>>> ten_words_list ['some', 'very', 'big', 'list', 'thatconsists', 'of', 'exactly', 'ten', 'words'] -
В 4-ом фрагменте не возникло
AssertionError, потому что вместо "проверки" отдельного выраженияa == b, мы "проверяем" весь кортеж. Следующий фрагмент прояснит ситуацию,>>> a = "python" >>> b = "javascript" >>> assert a == b Traceback (most recent call last): File "<stdin>", line 1, in <module> AssertionError >>> assert (a == b, "Values are not equal") <stdin>:1: SyntaxWarning: assertion is always true, perhaps remove parentheses? >>> assert a == b, "Values are not equal" Traceback (most recent call last): File "<stdin>", line 1, in <module> AssertionError: Values are not equal -
Что касается пятого фрагмента, то большинство методов, изменяющих элементы последовательности/маппингов, такие как
list.append,dict.update,list.sortи т. д., изменяют объекты на месте и возвращаютNone. Это делается для того, чтобы повысить производительность, избегая создания копии объекта, если операция может быть выполнена на месте (подробнее в документации). -
Последнее должно быть достаточно очевидным, изменяемый объект (например,
list) может быть изменен в функции, а переназначение неизменяемого (a -= 1) не является изменением значения. -
Знание этих тонкостей может сэкономить вам часы отладки в долгосрочной перспективе.
▶ Сплиты (splitsies) *
>>> 'a'.split()
['a']
# эквивалентно
>>> 'a'.split(' ')
['a']
# но
>>> len(''.split())
0
# не эквивалентно
>>> len(''.split(' '))
1
💡 Объяснение
- Может показаться, что разделителем по умолчанию для split является одиночный пробел
' ', но согласно документацииесли sep не указан или равен
none, применяется другой алгоритм разбиения: последовательные пробельные символы рассматриваются как один разделитель, и результат не будет содержать пустых строк в начале или конце, если в строке есть ведущие или завершающие пробелы. Следовательно, разбиение пустой строки или строки, состоящей только из пробельных символов, с разделителем none возвращает[]. если задан sep, то последовательные разделители не группируются вместе и считаются разделителями пустых строк (например,'1,,2'.split(',')возвращает['1', '', '2']). Разделение пустой строки с указанным разделителем возвращает['']. - Обратите внимание, как обрабатываются ведущие и завершающие пробелы в следующем фрагменте,
>>> ' a '.split(' ') ['', 'a', ''] >>> ' a '.split() ['a'] >>> ''.split(' ') ['']
▶ Подстановочное импортирование (wild imports) *
# File: module.py
def some_weird_name_func_():
print("works!")
def _another_weird_name_func():
print("works!")
Результат
>>> from module import *
>>> some_weird_name_func_()
"works!"
>>> _another_weird_name_func()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name '_another_weird_name_func' is not defined
💡 Объяснение:
-
Часто рекомендуется не использовать импорт с подстановочными знаками (wildcard import). Первая очевидная причина заключается в том, что при импорте с подстановочным знаком имена с ведущим подчеркиванием не импортируются. Это может привести к ошибкам во время выполнения.
-
Если бы мы использовали синтаксис
from ... import a, b, c, приведенная вышеNameErrorне возникла бы.>>> from module import some_weird_name_func_, _another_weird_name_func >>> _another_weird_name_func() works! -
Если вы действительно хотите использовать импорт с подстановочными знаками, то нужно определить список
__all__в вашем модуле, который будет содержать публичные объекты, доступные при wildcard импортировании.__all__ = ['_another_weird_name_func'] def some_weird_name_func_(): print("works!") def _another_weird_name_func(): print("works!")Результат
>>> _another_weird_name_func() "works!" >>> some_weird_name_func_() Traceback (most recent call last): File "<stdin>", line 1, in <module> NameError: name 'some_weird_name_func_' is not defined
▶ Все ли отсортировано? *
>>> x = 7, 8, 9
>>> sorted(x) == x
False
>>> sorted(x) == sorted(x)
True
>>> y = reversed(x)
>>> sorted(y) == sorted(y)
False
💡 Объяснение:
-
Метод
sortedвсегда возвращает список, а сравнение списка и кортежа всегда возвращаетFalse. -
>>> [] == tuple() False >>> x = 7, 8, 9 >>> type(x), type(sorted(x)) (tuple, list) -
В отличие от метода
sorted, методreversed` возвращает итератор. Почему? Потому что сортировка требует, чтобы итератор либо изменялся на месте, либо использовал дополнительный контейнер (список), в то время как реверсирование может работать просто путем итерации от последнего индекса к первому. -
Поэтому при сравнении
sorted(y) == sorted(y)первый вызовsorted()будет потреблять итераторy, а следующий вызов просто вернет пустой список.>>> x = 7, 8, 9 >>> y = reversed(x) >>> sorted(y), sorted(y) ([7, 8, 9], [])
▶ Полночи не существует?
from datetime import datetime
midnight = datetime(2018, 1, 1, 0, 0)
midnight_time = midnight.time()
noon = datetime(2018, 1, 1, 12, 0)
noon_time = noon.time()
if midnight_time:
print("Time at midnight is", midnight_time)
if noon_time:
print("Time at noon is", noon_time)
Результат (< 3.5):
('Time at noon is', datetime.time(12, 0))
Полночное время не выведено.
💡 Объяснение:
До Python 3.5 булево значение для объекта datetime.time считалось False, если оно представляло полночь по UTC. При использовании синтаксиса if obj: для проверки того, что obj является null или эквивалентом "пусто", возникает ошибка.
Секция: Скрытые сокровища!
Секция содержит менее известные интересные нюансы работы Python, которые неизвестны большинству новичков.
▶ Python, можешь ли ты помочь взлелеть?
Что ж, поехали
import antigravity
Результат: Sshh... It's a super-secret.
💡 Объяснение:
- Модуль
antigravity- одно из немногих пасхальных яиц, выпущенных разработчиками Python. import antigravityоткрывает веб-браузер, указывающий на классический комикс XKCD о Python.- Это еще не все. Внутри пасхального яйца находится еще одно пасхальное яйцо. Если вы посмотрите на код, там определена функция, которая якобы реализует алгоритм геохашинга XKCD.
▶ goto, но почему?
from goto import goto, label
for i in range(9):
for j in range(9):
for k in range(9):
print("I am trapped, please rescue!")
if k == 2:
goto .breakout # выход из глубоко вложенного цикла
label .breakout
print("Freedom!")
Результат (Python 2.3):
I am trapped, please rescue!
I am trapped, please rescue!
Freedom!
💡 Объяснение:
- Рабочая версия
gotoв Python была анонсирована в качестве первоапрельской шутки 1 апреля 2004 года. - В текущих версиях Python этот модуль отсутствует.
- Хотя он работает, но, пожалуйста, не используйте его. Вот причина того, почему
gotoотсутствует в Python.
▶ Держитесь!
Если вы относитесь к тем людям, которым не нравится использование пробелов в Python для обозначения диапазонов, вы можете использовать C-стиль {} импортировав это,
from __future__ import braces
Результат:
File "some_file.py", line 1
from __future__ import braces
SyntaxError: not a chance
Скобочки? Ни за что! Если это разочаровывало вас, используйте Java. Хорошо, еще одна удивительная вещь, можете ли вы найти ошибку
SyntaxError которая вызвана в модуле __future__ код?
💡 Объяснение:
- Модуль
__future__обычно используется для предоставления возможностей из будущих версий Python. Однако "будущее" в данном конкретном контексте - это ирония. - Это пасхальное яйцо, связанное с мнением сообщества по этому вопросу.
- Код на самом деле присутствует здесь в файле
future.c. - Когда компилятор CPython встречает оператор future, он сначала запускает соответствующий код в
future.c, а затем рассматривает его как обычный оператор импорта.
▶ Давайте познакомимся с дружелюбным Дядей Барри
Непереводимая игра слов: Friendly Language Uncle For Life (FLUFL)
Результат (Python 3.x)
>>> from __future__ import barry_as_FLUFL
>>> "Ruby" != "Python" # в этом нет сомнений
File "some_file.py", line 1
"Ruby" != "Python"
^
SyntaxError: invalid syntax
>>> "Ruby" <> "Python"
True
Вот так просто.
💡 Объяснение:
-
Это относится к PEP-401, выпущенному 1 Апреля 2009 (вы знаете, о чем это говорит).
-
Цитата из PEP-401
Признав, что оператор неравенства
!=в Python 3.0 был ужасной, вызывающей боль ошибкой, FLUFL восстанавливает оператор<>(ромб) в качестве единственного написания. -
У Дяди Барри было еще много чего рассказать в PEP; вы можете прочитать их здесь.
-
Это работает хорошо в интерактивной среде, но при запуске через файл python вызывает
SyntaxError(смотри этот issue). Однако вы можете обернуть оператор внутриevalилиcompile, чтобы заставить его работать (но зачем?)from __future__ import barry_as_FLUFL print(eval('"Ruby" <> "Python"'))
▶ Даже Python понимает, что любовь - это сложно.
import this
Подождите, что это (this) такое? Это любовь! ❤️
Результат:
Дзен Python, от Тима Петерса
Красивое лучше, чем уродливое.
Явное лучше, чем неявное.
Простое лучше, чем сложное.
Сложное лучше, чем запутанное.
Плоское лучше, чем вложенное.
Разреженное лучше, чем плотное.
Читаемость имеет значение.
Особые случаи не настолько особые, чтобы нарушать правила.
При этом практичность важнее безупречности.
Ошибки никогда не должны замалчиваться.
Если они не замалчиваются явно.
Встретив двусмысленность, отбрось искушение угадать.
Должен существовать один и, желательно, только один очевидный способ сделать это.
Хотя он поначалу может быть и не очевиден, если вы не голландец [^1].
Сейчас лучше, чем никогда.
Хотя никогда зачастую лучше, чем прямо сейчас.
Если реализацию сложно объяснить — идея плоха.
Если реализацию легко объяснить — идея, возможно, хороша.
Пространства имён — отличная штука! Будем делать их больше!
Это Дзен Python!
>>> love = this
>>> this is love
True
>>> love is True
False
>>> love is False
False
>>> love is not True or False
True
>>> love is not True or False; love is love # Love is complicated
True
💡 Объяснение:
- Модуль
thisв Python - это пасхальное яйцо для The Zen Of Python (PEP 20). - И если вы думаете, что это уже достаточно интересно, посмотрите реализацию this.py. Забавный факт - код для дзена нарушает сам себя (и это, вероятно, единственное место, где это происходит, но это не точно).
- Что касается утверждения
любовь не является истиной или ложью; любовь - это любовь, иронично, но описательно (если нет, пожалуйста, посмотрите примеры, связанные с операторамиisиis not).
▶ Да, оно существует!
Ключевое слово else в связвке с циклом for. Один из стандартных примеров:
def does_exists_num(l, to_find):
for num in l:
if num == to_find:
print("Exists!")
break
else:
print("Does not exist")
Результат:
>>> some_list = [1, 2, 3, 4, 5]
>>> does_exists_num(some_list, 4)
Exists!
>>> does_exists_num(some_list, -1)
Does not exist
Использование else блока во время обработки исключения. Пример,
try:
pass
except:
print("Exception occurred!!!")
else:
print("Try block executed successfully...")
Результат:
Try block executed successfully...
💡 Объяснение:
- Блок
elseпосле цикла выполняется только тогда, когда нет явногоbreakпосле всех итераций. Вы можете думать об этом как о блоке "nobreak". - Блок
elseпосле блокаtryтакже называется "блоком завершения", поскольку достижениеelseв оператореtryозначает, что блок попыток действительно успешно завершен.
▶ Многоточие *
def some_func():
Ellipsis
Результат
>>> some_func()
# Ни вывода, ни ошибки
>>> SomeRandomString
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'SomeRandomString' is not defined
>>> Ellipsis
Ellipsis
💡 Объяснение
-
В Python,
Ellipsis- глобальный встроенный объект, эквивалентный....>>> ... Ellipsis -
Многоточие может использоваться в нескольких случаях,
- В качестве заполнителя для кода, который еще не написан (аналогично оператору
pass) - В синтаксисе срезов (slices) для представления полных срезов в оставшемся направлении ``py
import numpy as np three_dimensional_array = np.arange(8).reshape(2, 2, 2) array([ [ [0, 1], [2, 3] ],
[ [4, 5], [6, 7] ]])
Таким образом, наш `трехмерный_массив` представляет собой массив массивов массивов. Допустим, мы хотим вывести второй элемент (индекс `1`) всех внутренних массивов, мы можем использовать `Ellipsis`, чтобы обойти все предыдущие измерения ```py >>> three_dimensional_array[:,::,1] array([[1, 3], [5, 7]]) >>> three_dimensional_array[..., 1] # использование Ellipsis. array([[1, 3], [5, 7]])Примечание: это будет работать для любого количества измерений. Можно даже выбрать срез в первом и последнем измерении и игнорировать средние (
n_dimensional_array[firs_dim_slice, ..., last_dim_slice])- В подсказках типов для указания только части типа (например,
(Callable[..., int]илиTuple[str, ...])) - Вы также можете использовать
Ellipsisв качестве аргумента функции по умолчанию (в случаях, когда вы хотите провести различие между сценариями "аргумент не передан" и "значение не передано").
- В качестве заполнителя для кода, который еще не написан (аналогично оператору
▶ Писконечность (Inpinity)
В заголовке нет ошибки, так и задумано, пожалуйста, не создавайте issue или pull request с изменением.
Результат (Python 3.x):
>>> infinity = float('infinity')
>>> hash(infinity)
314159
>>> hash(float('-inf'))
-314159
💡 Объяснение:
- Хэш бесконечности - 10⁵ x π.
- Интересно, что хэш
float('-inf')- "-10⁵ x π" в Python 3, тогда как в Python 2 - "-10⁵ x e".
▶ Давайте искажать
1.
class Yo(object):
def __init__(self):
self.__honey = True
self.bro = True
Результат:
>>> Yo().bro
True
>>> Yo().__honey
AttributeError: 'Yo' object has no attribute '__honey'
>>> Yo()._Yo__honey
True
2.
class Yo(object):
def __init__(self):
# Попробуем симметричные двойные подчеркивания в названии атрибута
self.__honey__ = True
self.bro = True
Результат:
>>> Yo().bro
True
>>> Yo()._Yo__honey__
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'Yo' object has no attribute '_Yo__honey__'
Почему обращение к Yo()._Yo__honey сработало?
3.
_A__variable = "Some value"
class A(object):
def some_func(self):
return __variable # переменная еще не инициализирована
Результат:
>>> A().__variable
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'A' object has no attribute '__variable'
>>> A().some_func()
'Some value'
💡 Объяснение:
- Искажение имени используется для предотвращения коллизий имен между различными пространствами имен.
- В Python интерпретатор изменяет (mangles) имена членов класса, начинающиеся с
__(двойное подчеркивание, оно же "дундер") и не заканчивающиеся более чем одним подчеркиванием в конце, добавляя перед ними_NameOfTheClass. - Таким образом, чтобы получить доступ к атрибуту
__honeyв первом фрагменте, мы должны были добавить_Yoспереди, что предотвратило бы конфликты с тем же атрибутомname, определенным в любом другом классе. - Но почему тогда это не сработало во втором фрагменте? Потому что при манипулировании именами исключаются имена, заканчивающиеся двойным подчеркиванием.
- Третий фрагмент также является следствием манипулирования именами. Имя
__variableв оператореreturn __variableбыло искажено до_A__variable, что также является именем переменной, которую мы объявили во внешней области видимости. - Кроме того, если длина искаженного имени превышает 255 символов, произойдет усечение (truncation).
Секция: Внешность обманчива!
▶ Пропускаем строки?
Результат:
>>> value = 11
>>> valuе = 32
>>> value
11
Что за дела?
Заметка: самый простой способ воспроизвести это - просто скопировать утверждения из приведенного выше фрагмента и вставить их в свой файл/оболочку.
💡 Объяснение
Некоторые незападные символы выглядят идентично буквам английского алфавита, но интерпретатор считает их разными.
>>> ord('е') # кириллическое 'е' (ye)
1077
>>> ord('e') # латинское 'e', используемое в английском языке и набираемое с помощью стандартной клавиатуры
101
>>> 'е' == 'е'
false
>>> value = 42 # латинское "е
>>> valuе = 23 # кириллическое "е", интерпретатор python 2.x вызовет здесь `syntaxerror`
>>> value
42
Встроенная функция ord() возвращает юникод кодовую точку символа, и разные кодовые позиции кириллического 'e' и латинского 'e' оправдывают поведение приведенного выше примера.
▶ Телепортация
# Прежде всего выполним `pip install numpy`.
import numpy as np
def energy_send(x):
# Инициализация numpy массива
np.array([float(x)])
def energy_receive():
# Возвращаем пустой numpy массив
return np.empty((), dtype=np.float).tolist()
Результат:
>>> energy_send(123.456)
>>> energy_receive()
123.456
Где моя Нобелевская премия?
💡 Объяснение:
- Обратите внимание, что массив
numpy, созданный в функцииenergy_send, не возвращается, так что место в памяти свободно для перераспределения. numpy.empty()возвращает следующий свободный участок памяти без его повторной инициализации. Этот участок памяти просто оказывается тем же самым, который был только что освобожден (обычно, но не всегда).
▶ Что-то не так...
def square(x):
"""
Простая функция по вычислению квадрата числа путем суммирования.
"""
sum_so_far = 0
for counter in range(x):
sum_so_far = sum_so_far + x
return sum_so_far
Результат (Python 2.x):
>>> square(10)
10
Разве не должно быть 100?
Заметка: Если у вас не получается воспроизвести это, попробуйте запустить файл mixed_tabs_and_spaces.py через оболочку.
💡 Объяснение
-
Не смешивайте табы и пробелы! Символ, непосредственно предшествующий return, является "табом", а код в других местах примера имеет отступ в 4 пробела.
-
Вот как Python обрабатывает табы:
Сначала табы заменяются (слева направо) на пробелы от одного до восьми так, чтобы общее количество символов до замены включительно было кратно восьми <...>.
-
Таким образом, "табы" в последней строке функции
squareзаменяется восемью пробелами, и она попадает в цикл. -
Python 3 достаточно любезен, чтобы автоматически выдавать ошибку для таких случаев.
Результат (Python 3.x):
TabError: inconsistent use of tabs and spaces in indentation
Секция: Разное
▶ += быстрее
# Использование "+", 3 строки:
>>> timeit.timeit("s1 = s1 + s2 + s3", setup="s1 = ' ' * 100000; s2 = ' ' * 100000; s3 = ' ' * 100000", number=100)
0.25748300552368164
# Использование "+=", 3 строки:
>>> timeit.timeit("s1 += s2 + s3", setup="s1 = ' ' * 100000; s2 = ' ' * 100000; s3 = ' ' * 100000", number=100)
0.012188911437988281
💡 Объяснение:
- Операнд
+=быстрее+для "сложения" 2 и более строк, так как первая строка (например,s1fors1 += s2 + s3) не уничтожается во время формирования финальной строки.
▶ Сделаем гигантскую строку!
def add_string_with_plus(iters):
s = ""
for i in range(iters):
s += "xyz"
assert len(s) == 3*iters
def add_bytes_with_plus(iters):
s = b""
for i in range(iters):
s += b"xyz"
assert len(s) == 3*iters
def add_string_with_format(iters):
fs = "{}"*iters
s = fs.format(*(["xyz"]*iters))
assert len(s) == 3*iters
def add_string_with_join(iters):
l = []
for i in range(iters):
l.append("xyz")
s = "".join(l)
assert len(s) == 3*iters
def convert_list_to_string(l, iters):
s = "".join(l)
assert len(s) == 3*iters
Результат:
# Фрагменты выполняются в оболочке `ipython` с использованием `%timeit` для лучшей читаемости результатов.
# Вы также можете использовать модуль timeit в обычной оболочке python shell/scriptm=, пример использования ниже
# timeit.timeit('add_string_with_plus(10000)', number=1000, globals=globals())
>>> NUM_ITERS = 1000
>>> %timeit -n1000 add_string_with_plus(NUM_ITERS)
124 µs ± 4.73 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
>>> %timeit -n1000 add_bytes_with_plus(NUM_ITERS)
211 µs ± 10.5 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
>>> %timeit -n1000 add_string_with_format(NUM_ITERS)
61 µs ± 2.18 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
>>> %timeit -n1000 add_string_with_join(NUM_ITERS)
117 µs ± 3.21 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
>>> l = ["xyz"]*NUM_ITERS
>>> %timeit -n1000 convert_list_to_string(l, NUM_ITERS)
10.1 µs ± 1.06 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Увеличим число итераций в 10 раз.
>>> NUM_ITERS = 10000
>>> %timeit -n1000 add_string_with_plus(NUM_ITERS) # Линейное увеличение времени выполнения
1.26 ms ± 76.8 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
>>> %timeit -n1000 add_bytes_with_plus(NUM_ITERS) # Квадратичное увеличение
6.82 ms ± 134 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
>>> %timeit -n1000 add_string_with_format(NUM_ITERS) # Линейное увеличение
645 µs ± 24.5 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
>>> %timeit -n1000 add_string_with_join(NUM_ITERS) # Линейное увеличение
1.17 ms ± 7.25 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
>>> l = ["xyz"]*NUM_ITERS
>>> %timeit -n1000 convert_list_to_string(l, NUM_ITERS) # Линейное увеличение
86.3 µs ± 2 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
💡 Объяснение
-
Подробнее о timeit или %timeit вы можете прочитать по этим ссылкам. Они используются для измерения времени выполнения фрагментов кода.
-
Не используйте
+для генерации длинных строк - В Pythonstrнеизменяема, поэтому левая и правая строки должны быть скопированы в новую строку для каждой пары конкатенаций. Если вы конкатенируете четыре строки длины 10, то вместо 40 символов вы скопируете (10+10) + ((10+10)+10) + (((10+10)+10)+10) = 90 символов. С увеличением количества и размера строки ситуация ухудшается в квадратичной прогрессии (что подтверждается временем выполнения функцииadd_bytes_with_plus). -
Поэтому рекомендуется использовать синтаксис
.format.или%(правда, для очень коротких строк они немного медленнее, чем+). -
Или лучше, если у вас уже есть содержимое в виде итерируемого объекта, тогда используйте
''.join(iterable_object), что гораздо быстрее. -
В отличие от
add_bytes_with_plusиз-за оптимизаций+=, рассмотренных в предыдущем примере,add_string_with_plusне показало квадратичного увеличения времени выполнения. Если бы оператор былs = s + "x" + "y" + "z"вместоs += "xyz", увеличение было бы квадратичным.def add_string_with_plus(iters): s = "" for i in range(iters): s = s + "x" + "y" + "z" assert len(s) == 3*iters >>> %timeit -n100 add_string_with_plus(1000) 388 µs ± 22.4 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each) >>> %timeit -n100 add_string_with_plus(10000) # Quadratic increase in execution time 9 ms ± 298 µs per loop (mean ± std. dev. of 7 runs, 100 loops each) -
Такое число способов форматирования и создания гигантской строки несколько противоречит Zen of Python, согласно которому,
должен быть один - и желательно только один - очевидный способ сделать это.
▶ Замедляем поиск по dict *
some_dict = {str(i): 1 for i in range(1_000_000)}
another_dict = {str(i): 1 for i in range(1_000_000)}
Результат:
>>> %timeit some_dict['5']
28.6 ns ± 0.115 ns per loop (mean ± std. dev. of 7 runs, 10000000 loops each)
>>> some_dict[1] = 1
>>> %timeit some_dict['5']
37.2 ns ± 0.265 ns per loop (mean ± std. dev. of 7 runs, 10000000 loops each)
>>> %timeit another_dict['5']
28.5 ns ± 0.142 ns per loop (mean ± std. dev. of 7 runs, 10000000 loops each)
>>> another_dict[1] # Пытаемся получить значение по несуществующему ключу
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 1
>>> %timeit another_dict['5']
38.5 ns ± 0.0913 ns per loop (mean ± std. dev. of 7 runs, 10000000 loops each)
Почему одни и те же выражения становятся медленнее?
💡 Объяснение:
- В CPython есть общая функция поиска по словарю, которая работает со всеми типами ключей (
str,int, любой объект ...), и специализированная для распространенного случая словарей, состоящих только изstr-ключей. - Специализированная функция (названная
lookdict_unicodeв исходный код CPython) знает, что все существующие ключи (включая искомый ключ) являются строками, и использует более быстрое и простое сравнение строк для сравнения ключей, вместо вызова метода__eq__. - При первом обращении к экземпляру
dictс ключом, не являющимсяstr, он модифицируется, чтобы в дальнейшем для поиска использовалась общая функция. - Этот процесс не обратим для конкретного экземпляра
dict, и ключ даже не обязательно должен существовать в словаре. Поэтому попытка неудачного поиска имеет тот же эффект.
▶ Раздуваем экземпляры словарей *
import sys
class SomeClass:
def __init__(self):
self.some_attr1 = 1
self.some_attr2 = 2
self.some_attr3 = 3
self.some_attr4 = 4
def dict_size(o):
return sys.getsizeof(o.__dict__)
Результат: (Python 3.8, другие версии Python 3 могут немного отличаться)
>>> o1 = SomeClass()
>>> o2 = SomeClass()
>>> dict_size(o1)
104
>>> dict_size(o2)
104
>>> del o1.some_attr1
>>> o3 = SomeClass()
>>> dict_size(o3)
232
>>> dict_size(o1)
232
Попробуем снова... В новом сессии интерпретатора:
>>> o1 = SomeClass()
>>> o2 = SomeClass()
>>> dict_size(o1)
104 # как ожидается
>>> o1.some_attr5 = 5
>>> o1.some_attr6 = 6
>>> dict_size(o1)
360
>>> dict_size(o2)
272
>>> o3 = SomeClass()
>>> dict_size(o3)
232
Что заставляет эти словари раздуваться? И почему только созданные объекты также раздуваются?
💡 Объяснение:
- CPython может повторно использовать один и тот же объект "keys" в нескольких словарях. Это было добавлено в PEP 412 с целью сокращения использования памяти, особенно в экземплярах словарей - где ключи (атрибуты экземпляра), как правило, общие для всех экземпляров.
- Эта оптимизация совершенно беспроблемна для экземпляров словарей, но она не работает, если нарушены некоторые условия.
- Словари с общим доступом к ключам не поддерживают удаление; если атрибут экземпляра удаляется, словарь становится "не общим", и общий доступ к ключам отключается для всех последующих экземпляров того же класса.
- Кроме того, если размер ключей словаря был изменен (из-за вставки новых ключей), они остаются общими только если они используются только одним словарем (это позволяет добавить много атрибутов в
__init__самого первого созданного экземпляра, не вызывая "unshare"). Если на момент изменения размера существует несколько экземпляров, совместное использование ключей отключается для всех последующих экземпляров одного класса: CPython не может определить, используют ли ваши экземпляры один и тот же набор атрибутов, и решает отказаться от попытки поделиться ключами. - Небольшой совет, если вы стремитесь уменьшить занимаемый программой объем памяти: не удаляйте атрибуты экземпляров и обязательно инициализируйте все атрибуты в
__init__!
▶ Минорное *
-
join()- строковая операция вместо списочной. (может показаться неочевидным при первом использовании)💡 Объяснение: Если
join()- это строковый метод, то он может работать с любым итеруемыми объектами (список, кортеж, итераторы). Если бы это был списковый метод, то его пришлось бы реализовывать отдельно для каждого типа. Кроме того, нет особого смысла помещать метод, специфичный для строки, в общий API объектаlist. -
Несколько странных, но семантически правильных утверждений:
[] = ()- семантически корректное утверждение (распаковка пустогокортежав пустойсписок)'a'[0][0][0][0][0]также является семантически корректным утверждением, поскольку в Python строки являются последовательностями(итерируемыми объектами, поддерживающими доступ к элементам с использованием целочисленных индексов).3 --0-- 5 == 8и--5 == 5- оба семантически корректные утверждения и имеют значениеTrue.
-
Учитывая, что
a- это число,++aи--aявляются корректными утверждениями Python, но ведут себя не так, как аналогичные утверждения в таких языках, как C, C++ или Java.>>> a = 5 >>> a 5 >>> ++a 5 >>> --a 5💡 Объяснение:
- В грамматике Python нет оператора
++. На самом деле это два оператора+. ++aпреобразуется в+(+a), а затем вa. Аналогично для утверждения--a.- На StackOverflow обсуждается обоснование отсутствия операторов инкремента и декремента в Python.
- В грамматике Python нет оператора
-
Вы наверняка знаете об операторе Walrus в Python. Но слышали ли вы когда-нибудь об операторе пространственного инкремента?
>>> a = 42 >>> a -=- 1 >>> a 43Он используется как альтернативный оператор инкрементации, вместе с другим оператором
>>> a +=+ 1 >>> a >>> 44💡 Объяснение: Этот розыгрыш взят из твита Raymond Hettinger. На самом деле оператор захвата пространства - это просто неправильно отформатированное
a -= (-1). Что эквивалентноa = a - (- 1). Аналогично для случаяa += (+ 1). -
В Python есть недокументированный оператор обратная импликация.
>>> False ** False == True True >>> False ** True == False True >>> True ** False == True True >>> True ** True == True True💡 Объяснение: Если заменить
FalseиTrueна 0 и 1 и произвести математические вычисления, то таблица истинности будет эквивалентна оператору обратной импликации. (Источник) -
Раз уж мы заговорили об операторах, есть еще оператор
@для умножения матриц (не волнуйтесь, на этот раз он настоящий).>>> import numpy as np >>> np.array([2, 2, 2]) @ np.array([7, 8, 8]) 46💡 Объяснение: Оператор
@был добавлен в Python 3.5 с учетом пожеланий научного сообщества. Любой объект может перегрузить магический метод__matmul__, чтобы определить поведение этого оператора. -
Начиная с Python 3.8 для быстрой отладки можно использовать типичный синтаксис f-строк, например
f'{some_var=}. Пример,>>> some_string = "wtfpython" >>> f'{some_string=}' "some_string='wtfpython'" -
Python использует 2 байта для хранения локальных переменных в функциях. Теоретически это означает, что в функции может быть определено только 65536 переменных. Однако в python есть удобное решение, которое можно использовать для хранения более 2^16 имен переменных. Следующий код демонстрирует, что происходит в стеке, когда определено более 65536 локальных переменных (Внимание: этот код печатает около 2^18 строк текста, так что будьте готовы!):
import dis exec(""" def f(): """ + """ """.join(["X" + str(x) + "=" + str(x) for x in range(65539)])) f() print(dis.dis(f)) -
Несколько потоков Python не смогут выполнять ваш Python-код одновременно (да, вы не ослышались!). Может показаться интуитивно понятным породить несколько потоков и позволить им выполнять ваш Python код одновременно, но из-за Global Interpreter Lock в Python, все, что вы делаете, это заставляете ваши потоки выполняться на одном и том же ядре по очереди. Потоки Python хороши для задач, связанных с IO, но чтобы добиться реального распараллеливания в Python для задач, связанных с процессором, вы можете использовать модуль Python multiprocessing.
-
Иногда метод
printможет выводить значения с задержкой. Например,# Файл some_file.py import time print("wtfpython", end="_") time.sleep(3)Это выведет
wtfpythonчерез 3 секунды из-за аргументаend, потому что выходной буфер очищается либо при появлении\n, либо когда программа завершает выполнение. Мы можем принудительно отчистить буфер, передав аргументflush=True. -
Срез списка индексом, превышающим длину списка, не приводит к ошибкам
>>> some_list = [1, 2, 3, 4, 5] >>> some_list[111:] [] -
При срезе итерируемого объекта не всегда создается новый объект. Например,
>>> some_str = "wtfpython" >>> some_list = ['w', 't', 'f', 'p', 'y', 't', 'h', 'o', 'n'] >>> some_list is some_list[:] # Ожидается False, так как создан новый объект. False >>> some_str is some_str[:] # Возвращается True, потому что строки неизменны, создание нового объекта ничего не меняет True -
int('١٢٣٤٥٦٧٨٩')возвращает123456789в Python 3. В Python десятичные символы включают в себя символы цифр и все символы, которые могут быть использованы для формирования десятично-радиксных чисел, например U+0660, ARABIC-INDIC DIGIT ZERO. Вот интересная история, связанная с таким поведением Python. -
Начиная с Python 3 вы можете разделять числовые литералы символами подчеркивания (для лучшей читаемости).
>>> six_million = 6_000_000 >>> six_million 6000000 >>> hex_address = 0xF00D_CAFE >>> hex_address 4027435774 -
'abc'.count('') == 4. Вот примерная реализация методаcount, которая немного разъяснит ситуациюdef count(s, sub): result = 0 for i in range(len(s) + 1 - len(sub)): result += (s[i:i + len(sub)] == sub) return resultТакое поведение связано с совпадением пустой подстроки(
'') со срезами длины 0 в исходной строке.
Вклад в проект
Как можно внести свой вклад в развитие wtfpython,
- Предложить новые примеры
- Помочь в переводе (См. issues labeled translation)
- Мелкие исправления, такие как указание на устаревшие фрагменты, опечатки, ошибки форматирования и т.д.
- Выявление пробелов (таких как недостаточное объяснение, избыточные примеры и т. д.)
- Любые творческие предложения, чтобы сделать этот проект более интересным и полезным.
Пожалуйста, смотрите CONTRIBUTING.md для более подробной информации. Не стесняйтесь создать новый issue для обсуждения.
PS: Пожалуйста, не обращайтесь к нам с просьбами об обратной ссылке, ссылки не будут добавлены, если они не имеют отношения к проекту.
Благодарности
Идея и дизайн этой коллекции были изначально вдохновлены потрясающим проектом Дениса Дована wtfjs. Подавляющая поддержка со стороны питонистов придала проекту ту форму, в которой он находится сейчас.
Несколько хороших ссылок!
- https://www.youtube.com/watch?v=sH4XF6pKKmk
- https://www.reddit.com/r/Python/comments/3cu6ej/what_are_some_wtf_things_about_python
- https://sopython.com/wiki/Common_Gotchas_In_Python
- https://stackoverflow.com/questions/530530/python-2-x-gotchas-and-landmines
- https://stackoverflow.com/questions/1011431/common-pitfalls-in-python
- https://www.python.org/doc/humor/
- https://github.com/cosmologicon/pywat#the-undocumented-converse-implication-operator
- https://www.codementor.io/satwikkansal/python-practices-for-efficient-code-performance-memory-and-usability-aze6oiq65
- https://github.com/wemake-services/wemake-python-styleguide/search?q=wtfpython&type=Issues
- Ветки обсуждения WFTPython на Hacker News и Reddit.
🎓 Лицензия
![]()
Удиви своих друзей!
Если вам нравится wtfpython, вы можете поделиться проектом, используя быстрые ссылки,
Нужна PDF версия?
Я получил несколько запросов на pdf (и epub) версию wtfpython. Вы можете добавить свои данные здесь, чтобы получить их, как только они будут готовы.
Вот и все, друзья! Для получения новых материалов, подобных этому, вы можете добавить свой email сюда.