436: Speed up the word prefix databases computation time r=Kerollmops a=Kerollmops
This PR depends on the fixes done in #431 and must be merged after it.
In this PR we will bring the `WordPrefixPairProximityDocids`, `WordPrefixDocids` and, `WordPrefixPositionDocids` update structures to a new era, a better era, where computing the word prefix pair proximities costs much fewer CPU cycles, an era where this update structure can use the, previously computed, set of new word docids from the newly indexed batch of documents.
---
The `WordPrefixPairProximityDocids` is an update structure, which means that it is an object that we feed with some parameters and which modifies the LMDB database of an index when asked for. This structure specifically computes the list of word prefix pair proximities, which correspond to a list of pairs of words associated with a proximity (the distance between both words) where the second word is not a word but a prefix e.g. `s`, `se`, `a`. This word prefix pair proximity is associated with the list of documents ids which contains the pair of words and prefix at the given proximity.
The origin of the performances issue that this struct brings is related to the fact that it starts its job from the beginning, it clears the LMDB database before rewriting everything from scratch, using the other LMDB databases to achieve that. I hope you understand that this is absolutely not an optimized way of doing things.
Co-authored-by: Clément Renault <clement@meilisearch.com>
Co-authored-by: Kerollmops <clement@meilisearch.com>
451: Update LICENSE with Meili SAS name r=Kerollmops a=curquiza
Check with thomas, we must put the real name of the company
Co-authored-by: Clémentine Urquizar - curqui <clementine@meilisearch.com>
450: Get rid of chrono in favor of time r=Kerollmops a=irevoire
We only use `chrono` as a wrapper around `time`, and since there has been an [open CVE on `chrono` for at least 3 months now](https://github.com/chronotope/chrono/pull/632) and the repo seems to be [struggling with maintenance](https://github.com/chronotope/chrono/pull/639), I think we should use `time` directly which is way more active and sufficient for our use case.
EDIT: Actually the CVE status has been known for more than 6 months: https://github.com/chronotope/chrono/issues/602
Co-authored-by: Irevoire <tamo@meilisearch.com>
442: fix phrase search r=curquiza a=MarinPostma
Run the exact match search on 7 words windows instead of only two. This makes false positive very very unlikely, and impossible on phrase query that are less than seven words.
Co-authored-by: ad hoc <postma.marin@protonmail.com>
445: allow null values in csv r=Kerollmops a=MarinPostma
This pr allows null values in csv:
- if the field is of type string, then an empty field is considered null (`,,`), anything other is turned into a string (i.e `, ,` is a single whitespace string)
- if the field is of type number, when the trimmed field is empty, we consider the value null (i.e `,,`, `, ,` are both null numbers) otherwise we try to parse the number.
Co-authored-by: ad hoc <postma.marin@protonmail.com>
417: Change chunk size to 4MiB to fit more the end user usage r=Kerollmops a=ManyTheFish
Reverts meilisearch/milli#379
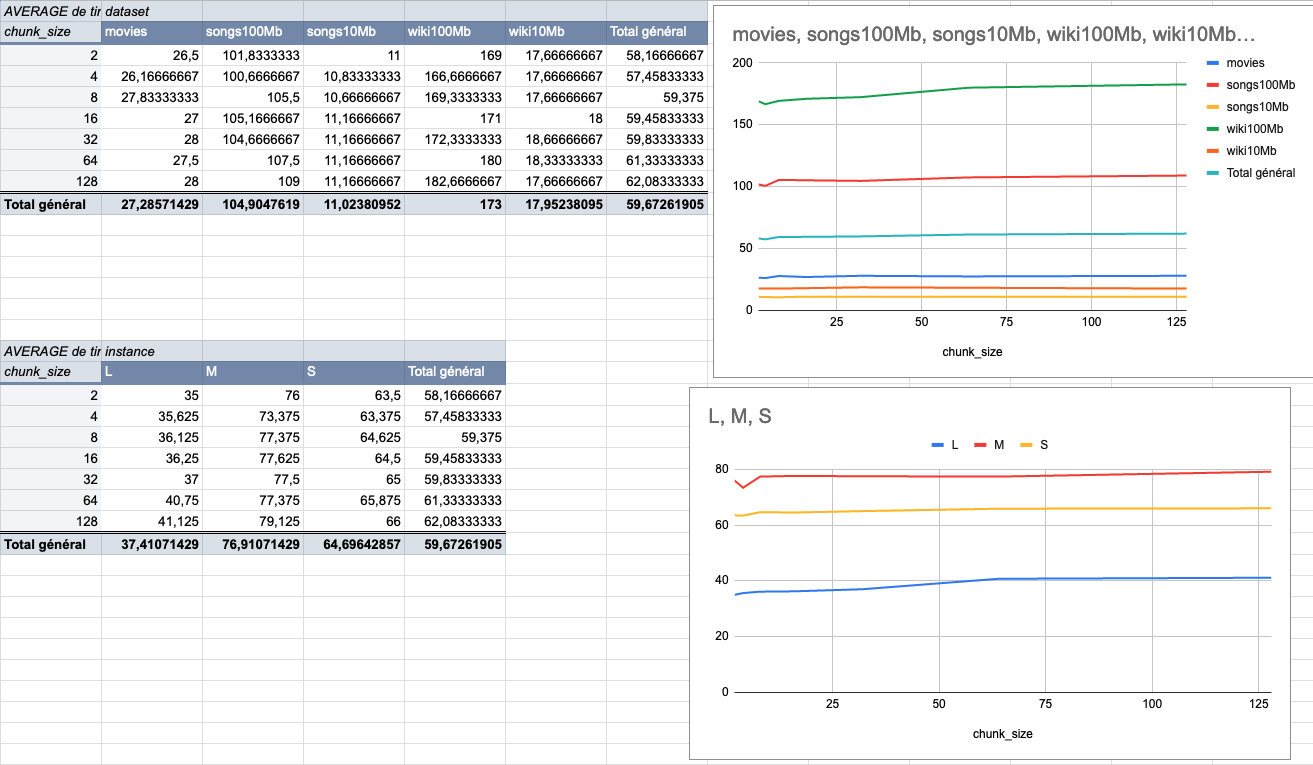
We made several indexing tests using different sizes of datasets (5 datasets from 9MiB to 100MiB) on several typologies of VMs (`XS: 1GiB RAM, 1 VCPU`, `S: 2GiB RAM, 2 VCPU`, `M: 4GiB RAM, 3 VCPU`, `L: 8GiB RAM, 4 VCPU`).
The result of these tests shows that the `4MiB` chunk size seems to be the best size compared to other chunk sizes (`2Mib`, `4MiB`, `8Mib`, `16Mib`, `32Mib`, `64Mib`, `128Mib`).
below is the average time per chunk size:

<details>
<summary>Detailled data</summary>
<br>
</br>
</details>
Co-authored-by: Many <many@meilisearch.com>
444: Fix the parsing of ndjson requests to index more than the first line r=Kerollmops a=Kerollmops
This PR correctly uses the `BufRead` trait to read every line of the content instead of just the first one. This bug was only affecting the http-ui test crate.
Co-authored-by: Kerollmops <clement@meilisearch.com>
431: Fix and improve word prefix pair proximity r=ManyTheFish a=Kerollmops
This PR first fixes the algorithm we used to select and compute the word prefix pair proximity database. The previous version was skipping nearly all of the prefixes. The issue is that this fix made this method to take more time and we were trying to reduce the time spent in it.
With `@ManyTheFish` we found out that we could skip some of the work we were doing by:
- discarding the prefixes that were shorter than a specific threshold (default: 2).
- discarding the word prefix pairs with proximity bigger than a specific threshold (default: 4).
- remove the unused threshold that was specifying a minimum amount of word docids to merge.
We will take more time to do some more optimization, like stop clearing and recomputing from scratch the database, we will compute the subsets of keys to create, keep and merge. This change is a little bit more complex than what this PR does.
I keep this PR as a draft as I want to further test the real gain if it is enough or not if it is valid or not. I advise reviewers to review commit by commit to see the changes bit by bit, reviewing the whole PR can be hard.
Co-authored-by: Clément Renault <clement@meilisearch.com>
441: Changes related to the rebranding r=curquiza a=meili-bot
_This PR is auto-generated._
- [X] Change the name `MeiliSearch` to `Meilisearch` in README.
- [x] ⚠️ Ensure the bot did not update part you don’t want it to update, especially in the code examples in the Getting started.
- [x] Please, ensure there is no other "MeiliSearch". For example, in the comments or in the tests name.
- [x] Put the new logo on the README if needed -> still using the milli logo so far
Co-authored-by: meili-bot <74670311+meili-bot@users.noreply.github.com>
Co-authored-by: Clémentine Urquizar <clementine@meilisearch.com>
438: CLI improvements r=Kerollmops a=MarinPostma
I've made the following changes to the cli:
- `settings-update` become `settings`, with two subcommands: `update` and `show`.
- `document-addition` becomes `documents` with a subcommands: `add` (I'll add a feature to list documents later)
- `search` now has an interactive mode `-i`
- search return the number of documents and the time it took to perform the search.
Co-authored-by: mpostma <postma.marin@protonmail.com>
{kind=link}
{kind=link}